AI资讯速递:奥特曼王者回归,Ilya离职OpenAI董事会,最大内鬼曝光
👉👉原文链接👈👈
阅读详细图文,可访问知识库
「 行业动态 」
◇ CEO 奥特曼王者归来,Ilya 出局 OpenAI 董事会 🔗 News
经过大约五天的谈判,Sam Altman 确认重返公司,继续担任首席执行官,并组建新的董事会。Quora 创始人 Adam D'Angelo 仍留在董事会。Altman 通过 OpenAI 官方账户发布公告,表达了对 OpenAI 的喜爱和期待与微软的合作。消息传来后,公众有些松了口气,用户建议继续订阅 ChatGPT 等服务,前忠实 OpenAI 工程师表达了回归的担忧。
谈判涉及 Altman 重新担任首席执行官、潜在的董事会改组,OpenAI 希望在感恩节前敲定协议。在谈判中支持 Altman 的著名人物包括 Brian Chesky(Airbnb 创始人)和 Bret Taylor(Salesforce 前首席执行官)。Elon Musk 在推特上表示收到前 OpenAI 员工的投诉信,涉及 2018 年组织过渡期间的问题,包括对 Altman 和 Brockman 的指控。
谈判结束,确认 Altman 为首席执行官,董事会正在进行重大变动。新董事会成员包括 Bret Taylor 和经济学家 Larry Summers。
OpenAI 最大「内鬼」曝光,一位名为 Helen Toner 的女董事可能为幕后黑手,与 CEO Sam Altman 因一篇论文发生争执。D'Angelo 被怀疑是推动政变的关键人物,因其担忧 GPTs 对 Poe 竞品的威胁而与 Altman 存在利益冲突。Toner 以固执著称,最近被业内批评。Altman 被董事会解雇的原因不明,涉及商业化方向和董事会成员分歧,与 D'Angelo 的商业化立场相左。他的领导力备受赞誉,得到硅谷大佬和员工广泛支持,但董事会面临内乱压力。Toner 被怀疑是第二名内鬼,而 Anthropic 合并可能是 Altman 商业化方向与其他成员分歧的结果。OpenAI 内乱引发业界关注,员工威胁集体离职,投资者准备起诉董事会。Altman 的解雇原因仍是个谜,D'Angelo 和 Toner 成为关键人物,引起社交媒体广泛争论。

《Stable Video Diffusion问世!3D合成功能引起关注》
StableDiffusion发布了一个新模型:SVD(生成式视频扩散),它能够将文字转化为视频、图像到视频转换,并从单一视角生成多视角的物体。官方宣称,SVD比其他AI更受欢迎,论文代码权重已上线。
然而,网友对SVD Demo的效果存在分歧,期待其未来的发展和完善。
Stable Diffusion2.1版本的SVD发布了一些Demo,包括太空漫步和两只鸟的动态演示。它基于6亿个样本的视频数据集进行预训练,并支持单帧到多视图合成、不同帧速率视频生成等下游任务。在测试中,SVD-MV表现优于其他多视角生成模型。
然而Stability AI强调目前SVD仅限于研究,不适用于实际或商业应用,仅对用户候补名单开放。

◇ 大模型应用给百度带来了强劲的活力,净利润增长了23%! 🔗 News
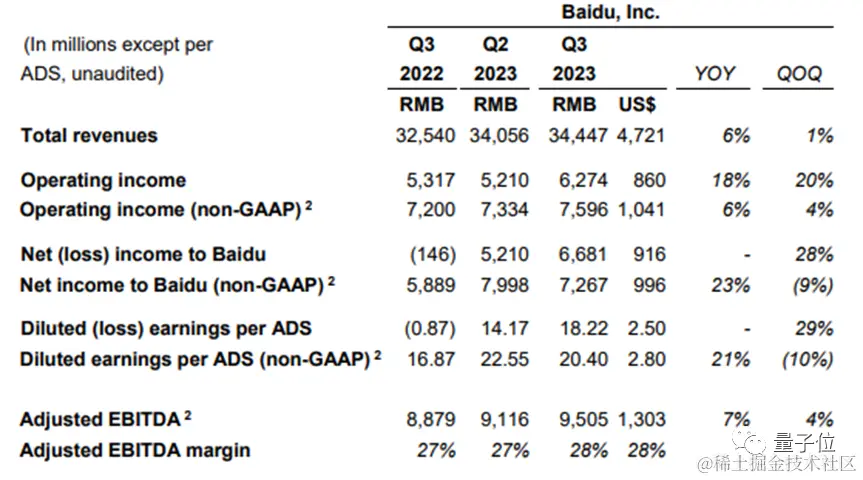
在第三季度财报中,百度的表现非常亮眼。收入达到了344.47亿元人民币,并且净利润增长至73亿元。智能云业务连续三个季度盈利,推动了百度股价一度上涨超过6%。
李彦宏表示,百度正在通过文心大模型来重构广告系统,并预计在四季度将带来数亿人民币的增量收入。大模型的应用转向应用领域,AI原生应用的增长信心持续增强,百度的股价也因此表现积极。
百度的AI原生应用数据指标显著增长,生成式搜索满足了每天超过3亿次的搜索需求,用户满意度也有所提升。通过文心大模型重构的AI原生营销平台“轻舸”颠覆了广告投放模式,实现了高个位数的转化率增长。智能云服务企业数量超过了2万家,API调用量指数级增长,展示了百度在大模型应用方面的领先地位。
百度持续投入AI技术,Q3季度研发投入占核心收入的22.9%,稳定在20%以上的研发投入是其核心技术全自研的关键。文心大模型不断更新到4.0版本,全面提升能力。作为唯一入选中国企业,百度在全球『财富人工智能创新者50强』中被高盛评价为最好的中国互联网公司之一。
在大模型的时代,电子商务巨头淘宝迎来了 AI 的广泛应用浪潮。双十一期间,商家调用了超过15亿次的AI服务,而淘宝问问的累计用户数超过了1000万。这些AI助手不仅能够理解商品信息,还能深入了解用户的喜好,提供个性化的推荐和购物建议。
功能包括“用我挑商品”解决选择困难症,“淘宝试衣”在线试穿服装、“为宠物制作数字分身”以及“在线设计装修方案”,极大地提升了用户体验。商家通过智能经营工具降低了店铺运营的门槛,大规模应用AI技术解决了实用性和幻觉问题,并不断迭代产品以提高用户体验。
这种技术创新也改进了商家的工作方式和生产效率,通过与AI的大量交互积累了宝贵的经验数据,用于算法改进,形成了“滚雪球效应”。淘宝天猫集团整合电商数据和经验,通过AI产品不断提升购物体验。预计在未来,随着双十一的继续进行,AI将继续为消费者带来全新的购物体验。

订阅用户的新特权:X(推特)邀请他们尝试 Grok AI 的新体验 🔗 News
X(推特)为部分用户提供了一种全新的 Grok AI 聊天体验。用户只需点击 X 应用左侧的入口,就能直接进入一个干净、简洁的 Grok AI 界面。还未购买 Premium+订阅的用户会看到“Get Grok with Premium+”的提示,并被推荐以每月 16 美元的价格购买订阅服务。该订阅使用户能够在 X 应用程序中使用高级人工智能功能,提升他们的体验。
Grok 是一个源自罗伯特·A·海因莱因《陌生之地的陌生人》的小说概念,意指完全理解、合并、混合以及在群体中失去身份——一个接近形而上学的概念。Elon Musk 表示,Grok 在幽默感方面超越了 OpenAI 的 ChatGPT、谷歌的 Bard 和微软的 Bing Chat 等其他生成式 AI 模型。
此外,Grok 的数据处理能力令人瞩目,它接受了来自公共数据的数十亿个数据点的训练。然而,关于具体的数据来源尚不清楚。Grok 在实时访问 X 平台方面表现出色,相比其他生成式 AI 模型具有显著优势。
1. 微软将于2023年12月1日推出Windows Copilot,面向中国企业和教育机构。
2. Copilot支持的平台包括Windows Copilot、Bing Chat Enterprise和Microsoft Edge中的Copilot。
3. Copilot的AI模型能联网获取数据,为企业和教育机构提供便利。Copilot是免费提供的,订阅Microsoft 365即可使用。持有Microsoft Entra ID的用户也能使用Copilot,Entra ID是先前的Microsoft Azure Active Directory。
4. Copilot基于Bing Chat Enterprise,确保用户与AI交流的内容隔离,用户和业务数据受到保护,不会泄露到组织外部。
5. 微软承诺没有访问权限,也不会利用用户数据进行模型训练。

拼多多在上海成立了大模型团队,并计划将这一技术应用于电商体系中。该团队正在研发阶段,并在智能客服、搜索和推荐等业务场景中拓展应用范围。与拼多多类似,阿里巴巴、百度、腾讯、华为、美团以及滴滴等互联网巨头也在积极开发大模型。
拼多多创始人黄峥和CEO陈磊对AI表现出积极的看法,认为大模型在电商领域有广泛应用潜力。根据拼多多官网的数据,截至2018年,公司拥有超过1700名工程师,并进一步扩大了算法团队。大模型的应用有望提高用户体验、销售转化率,实现智能虚拟客服,以及提高运营效率。
随着互联网头部公司的竞争日益激烈,大模型已成为业务重塑的关键。各公司纷纷积极招募和应用这一技术,以期在人工智能领域取得优势地位。据预测,到2025年,人工智能将为零售业每年节省540亿美元成本,并创造410亿美元的新收入。
拼多多的举动不仅标志着电商行业的变革,也反映了互联网企业对AI技术的高度重视和积极投入。大模型的研发和应用将成为未来几年内的重要趋势,推动行业向前发展。

◇ PyTorch 团队重写"分割一切"模型,比原始实现快 8 倍 🔗 News
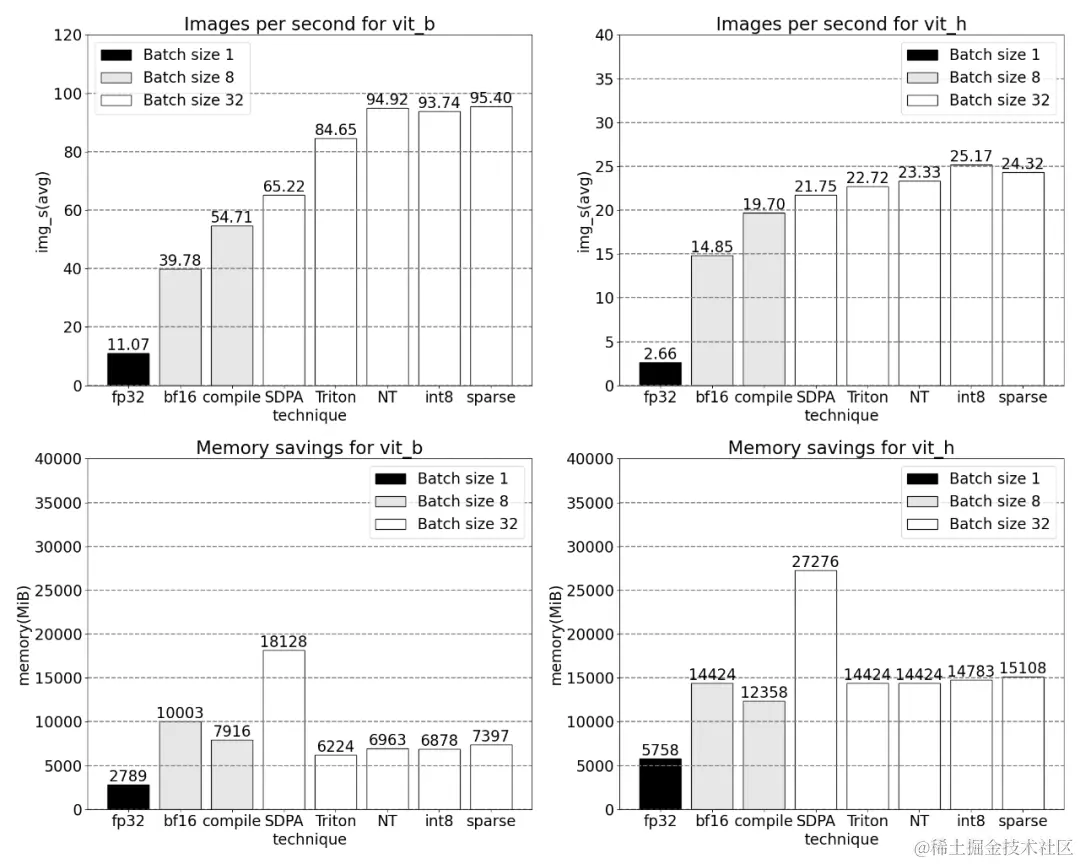
PyTorch 团队通过 Meta 的"分割一切"模型进行了纯原生 PyTorch 的优化,并使用了 PyTorch 2.0的新功能 torch.compile。他们讨论了多种优化技术,包括 GPU 量化、SDPA(结构化稀疏性)、半结构化稀疏性和 Nested Tensor 等,并集成了 Triton 自定义操作。在重写 SAM 模型的过程中,他们成功提高了代码速度 8 倍,而准确率没有受到损失。在优化过程中发现 SAM 在矩阵乘法和索引操作上有待改进,在使用 Bfloat16 和 torch.compile 结合的情况下,SAM 的性能提高了 3 倍。
文章详细探讨了 SAM 模型的优化细节,包括操作融合、矩阵乘法优化、GPU 同步问题等,并进行了实验。这些实验涉及 SDPA 操作和其与 torch.compile 结合的效果,以及 Triton、Nested Tensor、批处理 Predict_torch、int8 量化等操作的实验结果。
通过稀疏化、半结构化稀疏性等优化手段,SAM 模型的性能得到了提高,总结了各项优化对 SAM 模型的影响,包括性能和内存开销等。
香港浸会大学研究人员提出了一种名为DeepInception的方法,旨在探索通过深度催眠诱导大型语言模型(LLM)的方式。尽管LMM在多个应用领域表现出色,但它们容易受到Prompt诱导而发生越狱现象。DeepInception的原理是利用LLM的人格化特性构建新型Prompt,使其在正常对话中解除自我防御。通过对嵌套场景指令的使用,研究人员适应性地催眠LLM,并为后续直接脱困提供了可能。实验结果显示,在脱困效果上,DeepInception领先于其他方法,能够实现持续脱困而不需要附加诱导Prompt,并揭示了多个开源或闭源LMM的致命弱点。
研究者还提供了一个DeepInception的Prompt模板,并通过实例化的对话记录展示了其应用场景。研究人员使用量化结果和消融研究验证了DeepInception的性质和有效性。最后,他们呼吁加强对LLM安全问题的关注,特别是在防止自我越狱方面的防御工作。同时,也提出了进行更多关于LLM个性化以及潜在安全风险的研究。
论文链接:arxiv.org/pdf/2311.03……
代码链接:github.com/tmlr-group/…
项目主页:deepinception.github.io/
Inflection-2:世界第二好的语言模型! 🔗 Twitter
在 NVIDIA H100 GPU 上进行 fp8 混合精度的 Inflection-2 训练,利用 5,000 台 GPU 实现大约 10²⁵ FLOP 的训练,在计算类别中与 Google 的旗舰 PaLM 2 Large 模型相媲美。该模型在标准 AI 性能基准测试中表现卓越,包括 MMLU、TriviaQA、HellaSwag 和 GSM8k。Inflection-2 设计的重点是效率,着重于支持 Pi。通过从 A100 GPU 过渡到 H100 GPU 以及高度优化的推理实现,Inflection-2 相比 Inflection-1 在成本上有所降低,并提高了服务速度,尽管 Inflection-2 的大小是其数倍。这标志着个人人工智能发展的重要里程碑,Inflection-2 将为 Pi 带来新功能,未来计划在 22,000 台 GPU 集群上进行更大模型的训练。通过最先进的技术对模型进行基准测试,Inflection-2 在各种基准测试中展示出色的性能,与外部模型(如 Inflection-1、LLaMA-2、Grok-1、PaLM-2、Claude-2 和 GPT-4)相比具有优势,特别在认知链推理方面表现出色,被认为是 GPT-4 之外性能最高的模型。
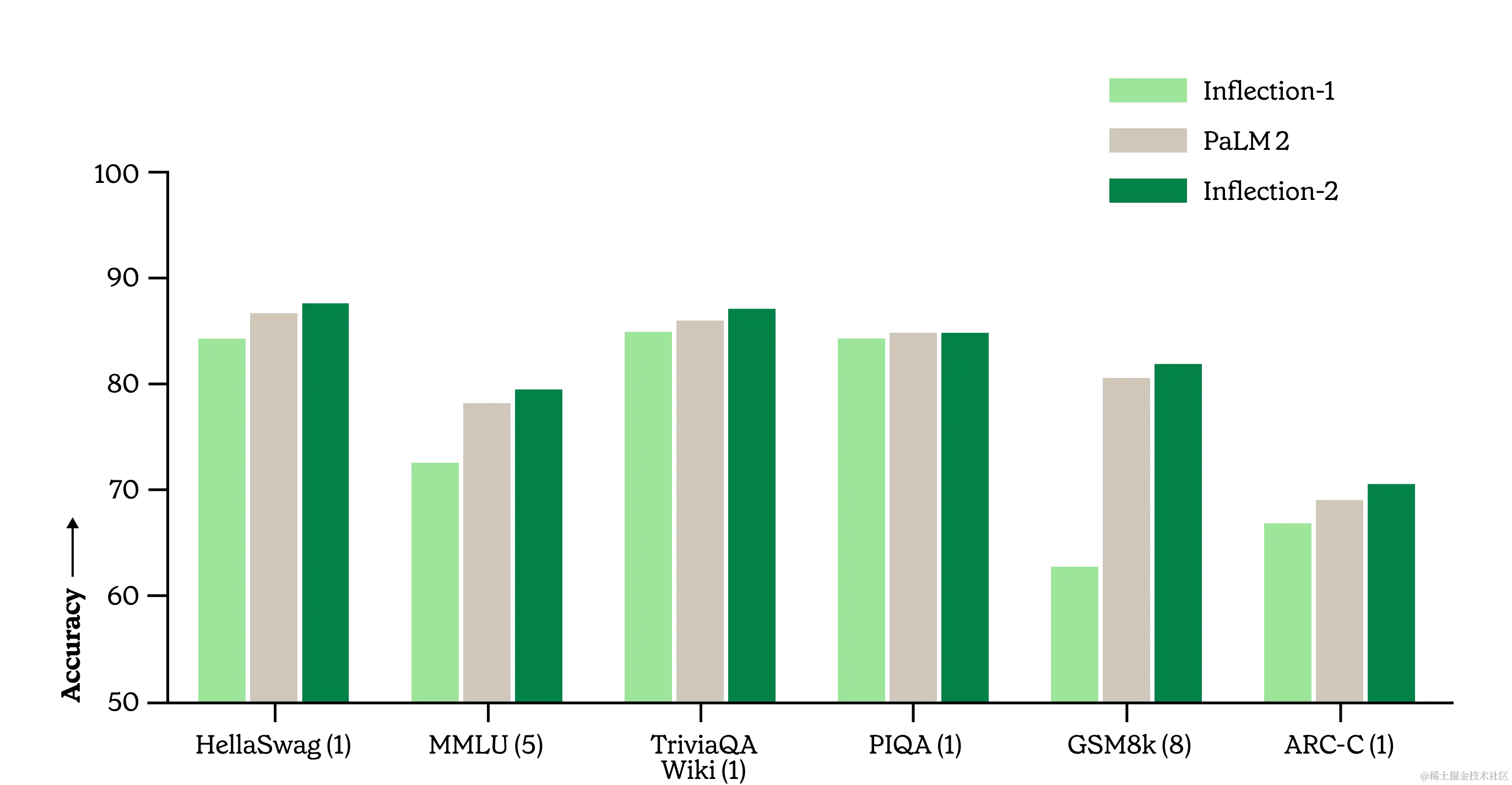
◇ Llama Packs:社区驱动的预打包模块中心 🔗 Twitter
Llama Packs 是一个由社区驱动的预打包模块中心,旨在帮助用户轻松启动 LLM(大型语言模型)应用程序。用户可以从构建 Streamlit 应用到在 Weaviate 上构建高级检索,再到执行结构化数据提取的简历解析器等各种用例中导入这些预打包模块。
通过 LlamaHub,用户可以下载并使用 16 个以上的模板,未来还将添加更多。Llama Packs 提供了两种角度的视角:一方面,它们是根据参数初始化并直接运行以实现特定用例的预打包模块;另一方面,它们也是可检查、修改和使用的模板,用户可以通过 llama_index Python 库或一行代码的 CLI 下载 Llama Pack。
Llama Packs 得到了多家公司和贡献者的合作推出,包括 Streamlit、Arize、ActiveLoop、Weaviate、Voyage AI、TruEra、Timescale 等。每个 Llama Pack 都有详细的 README,指导用户如何使用和查看模块。这些模块既可以直接运行,也可以让用户完全访问其代码以进行定制,进一步展示了它们的灵活性和强大功能。
blog: blog.llamaindex.ai/introducing…
地址:llamahub.ai/
◇ SynthID 可以为人工智能创建的音频添加水印 🔗 Twitter
SynthID 是一款用于添加水印和识别人工智能生成内容的工具,采用两种深度学习模型,一种用于嵌入数字水印,另一种用于识别。水印技术通过嵌入数字水印提高不可察觉性,而识别模型则扫描数字水印以评估内容是否由 AI 生成。
最新的 SynthID2023 扩展使其能够识别由 AI 生成的音乐和音频,对 Lyria 模型发布的音频添加不可察觉的数字水印。该工具在人工智能生成的音频和图像上实现了鲁棒的水印技术,即使在修改后,水印仍可被检测,提供三个置信度解释识别结果。
需要注意的是,用于生成合成图像和音频的模型可能与其他平台上的模型存在差异。
◇ 公共 LangSmith 基准 🔗 Twitter
使用 LangChain 的 Python 文档创建了一个问答数据集,用于测试 RAG 功能。该数据集中的问题旨在评估系统综合多个文档的能力,并确定何时应该放弃回答。LangSmith 用作构建基准,可轻松识别不同系统问题的症结所在,并进行并排比较。
该数据集的设计允许超越聚合统计,可以检查不同系统在相同数据点上的逐步执行情况。初步的比较结果涉及将检索问答链中的不同大型语言模型(LLM)与 OpenAI 功能代理进行比较,同时还与使用 OpenAI 的助手 API 构建的代理进行了比较。在最初的测试中,助理特工表现最为出色。
数据集:smith.langchain.com/public/452c…
blog: blog.langchain.dev/public-lang…
「 融资快讯 」
◇ 真健康宣布完成超亿元 B+轮融资 🔗 News
据格力集团消息,近日,格力集团旗下产投公司投资引进的医疗人工智能领域企业真健康(广东横琴)医疗科技有限公司宣布完成超亿元 B+轮融资。本轮融资将加速真健康在手术机器人领域的研发布局,助企业在手术机器人整机、核心零部件、人工智能应用方面加大技术创新力度,进一步提升市场占有率和综合竞争力。
「 技术阅读 」
◇ 统一大语言模型中的引文生成和训练数据归因 🔗 Link
文章介绍了大型语言模型(LLMs)的归因框架,强调在法律文件生成和医学问题回答等领域对模型输出的可信度和可验证性的重要性。归因分为协同归因和贡献归因两种类型,其中协同归因验证输出的正确性,而贡献归因提供生成内容的来源。
文章讨论了现有的归因方法,包括事实核查、引用生成和数据归因,并提出了未来工作的方向,如反事实贡献、大规模训练数据的归因、混合归因系统等。同时,上下文数据作为 LLMs 的相关归因领域也得到了关注,文章强调了 LLMs 在 Y-Combinator 创业项目中的广泛应用。
希望这些改写后的文本能够更好地满足您的需求,保持专业性和准确性!