富文本编辑器:从Prosemirror到Tiptap
在了解了富文本的基础知识后,我们开始探讨如何可视地修改 HTML 和 CSS 的过程。
首先,浏览器提供了 contenteditable 属性,使得元素可以被编辑。然而,这种方法并不适用于富文本编辑器,因为它是基于 JavaScript 进行动态更新的。
为了更有效地处理这些任务,富文本编辑器通常使用 document.execCommand 方法来控制可编辑内容的行为,并结合 contentEditable 使元素可编辑性更强。
然而,直接使用这两个能力进行富文本编辑是非常困难和不实用的。因此,大多数富文本编辑器都采用以下架构:
1. **内容editable**:提供一种全局可编辑的环境。
2. **document.execCommand**:允许 JavaScript 控制页面上的操作。
3. **组合应用**:结合以上两种技术来实现复杂的富文本编辑功能。
这种架构允许用户在特定区域进行编辑,并通过执行命令控制这些区域的行为。
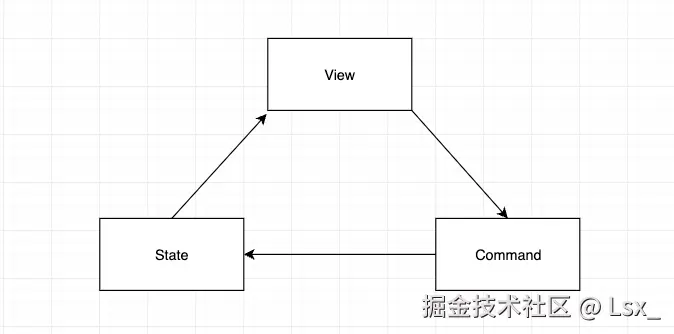
Prosemirror的核心由四个模块构成。
- `prosemirror-model`:定义编辑器的文档模型,用来描述编辑器内容的数据结构。
- `prosemirror-state`:描述编辑器的整体状态,包括文档数据、选择等。
- `prosemirror-view`:UI组件,用于将编辑器的状态展现为可编辑的元素,并处理用户交互。
- `prosemirror-transform`:修改文档的事务方法。
通过这些模块的对应关系,我们可以了解到Prosemirror的实现原理。本文将从state、view和transform三个方面探讨其原理。

在 Prosemirror 中,p 是一个节点,拥有三个子节点:`this is`、`string text with` 和 `emphasis`。非内容本身,如 `strong` 或 `em`,会以标记(mark)的形式存储在文本节点中。这种存储结构使文档从树状结构变成了 inline 的结构。
有一个核心好处是,如果使用 prosemirror 的存储结构,对于同一个既包含 `strong` 也包含 `em` 的文字,可以通过偏移量来描述位置,并且其数据结构就是唯一的。此外,通过这种方式,文档数据变得相对稳定,不会因为同时包含这两种标记而产生不稳定的问题。
除了上述优点外,这种数据结构还有其他的优势:
- 更符合用户对文本操作的直观感受,可以通过偏移量来描述位置,更加轻易地进行分割。
- 通过偏移量来操作性能上会比操作树要好很多。
### `state` 层
Prosemirror 的 `state` 并不是固定的,而是可以扩展的。但其有四个基本属性:`doc`、`selection`、`storedMarks` 和 `scrollToSelection`。其中最核心的是 `doc`,即文档数据,它存放的是文档的具体内容。
### `view` 层
在视图(view)调用 `updateState` (也就是根据 state 来更新视图)时,会调用节点的 `toDOM` 方法来创建 DOM 元素,从而渲染到浏览器上。相应的还有 `parseDOM` 方法,可以将 DOM 元素序列化成文档数据。
每次初始化或者有 state 有更新的时候,都会触发 `updateState` 方法,从而完成界面的更新。
### `transform` 层
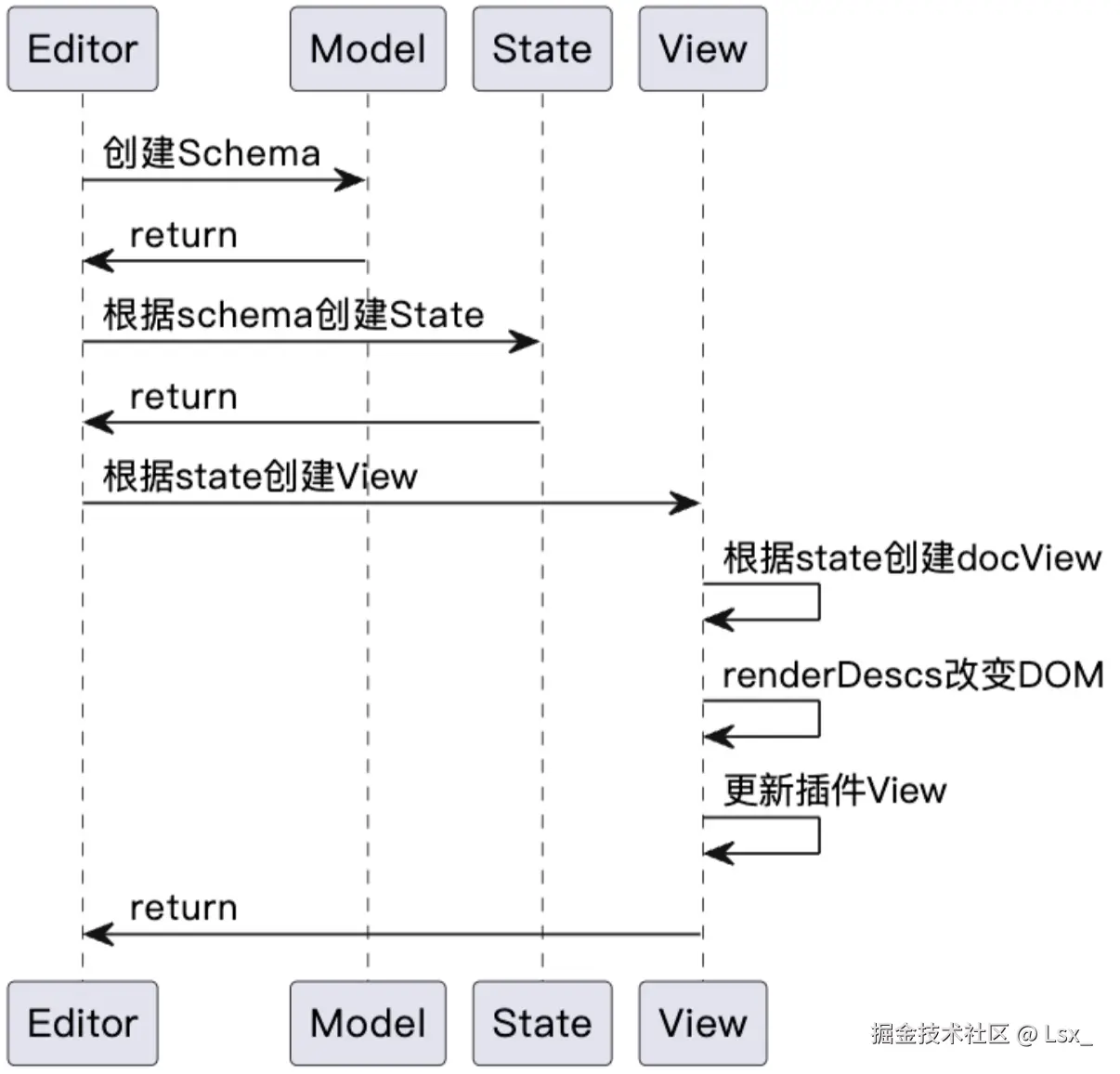
在更新流程中,当 view 变化时,会构建 transaction(其父类是 transform),来更新 state。Prosemirror 初始化流程:
首先看一下 Prosemirror 的初始化代码。
```javascript
// 创建schema
const demoSchema = new Schema({
nodes: addListNodes(schema.spec.nodes, "paragraph block*", "block"),
marks: schema.spec.marks
})
// 创建state
let state = EditorState.create({
doc: DOMParser.fromSchema(demoSchema).parse(document.querySelector("#content")),
plugins: exampleSetup({ schema: demoSchema })
})
// 创建view
let view = EditorView(document.querySelector('.full'), { state })
```
初始化先是创建文档数据的规范标准,类似约定了数据模型。其次创建了 `state`,这个 `state` 需要满足 `schema` 规范。最后根据 `state` 创建了 `view`,`view` 就是最终展现在用户面前的富文本编辑器 UI。
因为初始化的时候还没有用户操作的介入,所以并不涉及 command (transform) 的引入。
创建状态的代码片段:
```javascript
state = EditorState.create({
doc: DOMParser.fromSchema(demoSchema).parse(document.querySelector('#content')),
plugins: exampleSetup({ schema: demoSchema })
});
```
解释:上述代码展示了如何通过DOMParser解析富文本编辑器中的内容,并将其存储在状态对象的`doc`属性中。这个过程确保了界面与数据的一致性,特别是对于那些由用户动态添加的内容。
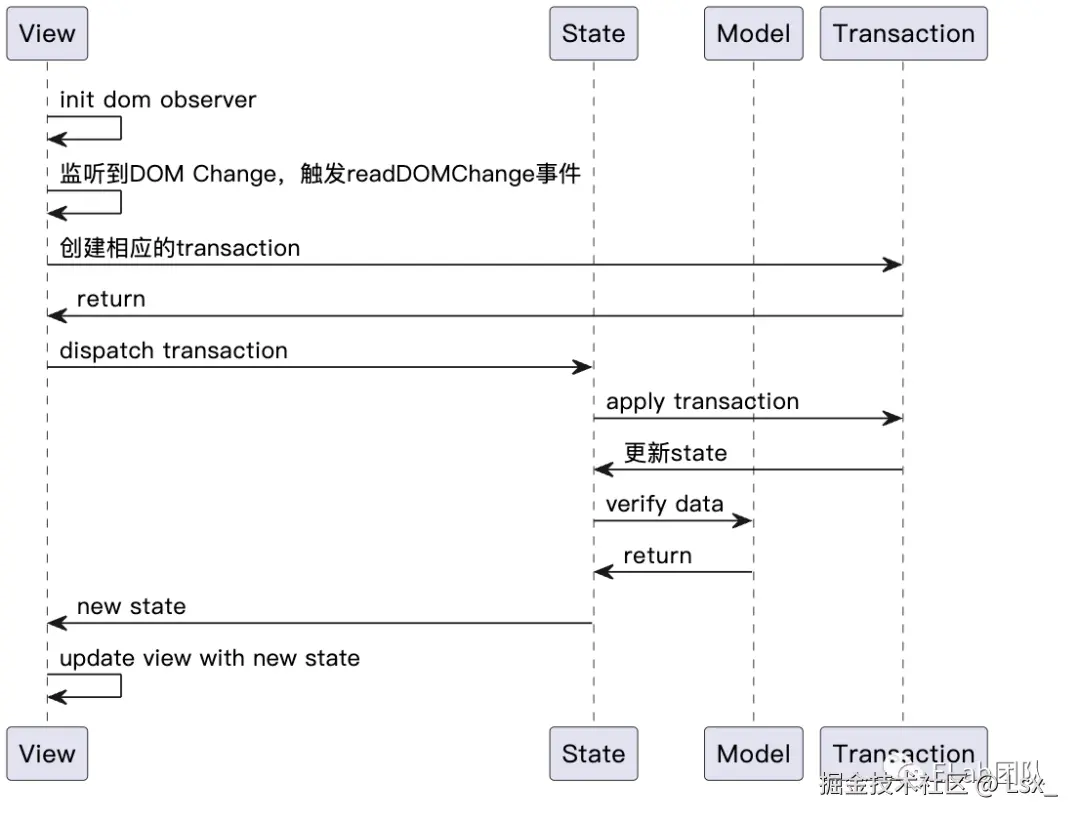
Prosemirror 更新流程:
当用户输入字符时,会发生以下更新操作:
1. 用户输入触发状态机中的事件监听器。
2. 触发一个更新函数来处理当前的文本内容变化。
3. 预先配置好的插件将根据新的内容调整编辑区域的布局和样式。
这些步骤确保了Prosemirror在用户修改文档时能够保持正确且一致的状态。
Tiptap是一款基于ProseMirror的富文本编辑器,以其灵活性和可扩展性受到关注。其优点包括:
- 基于ProseMirror:提供可靠的文档模型和编辑功能。
- 可扩展性:提供了丰富的插件系统,用户可以轻松创建自定义扩展和插件以满足特定需求。
- 易于定制:配置和定制非常灵活,可以根据需求调整编辑器的外观和功能。
- 社区支持:代码库维护良好,文档详尽,易于上手,并有活跃的社区和开发团队提供及时的支持和更新。
Tiptap提供了多种文本格式和样式,如粗体、斜体、下划线、列表等。同时,它还支持Markdown语法。
其优点包括:
- 基于Vue和React:提供了对这两个框架的良好支持,方便在这些框架中集成和使用。
- 实时协作:提供对实时协作编辑的支持,可以方便地集成多人协作功能。
- 配置灵活:提供了丰富的API接口,便于开发者进行二次开发。
通过使用Tiptap编辑器的扩展继承、自定义扩展等功能,可以构建出更为丰富和强大的富文本编辑器。