从键盘到智能:探索传统编程向人工智能生成内容(AIGC)的革命性跨越
### 前言
传统编程与AIGC(Artificial Intelligence Generated Content,人工智能生成内容)代表了软件开发和内容创造领域的两大技术范式。它们在目标、方法、技术应用及数据需求等方面存在显著差异。
---
### 处理数据类型与目标
#### 传统编程
通常针对结构化数据进行操作,如数据库中的表格数据,侧重于逻辑处理、数据分析和业务流程自动化。其目标在于实现特定功能,如数据查询、事务处理等,遵循明确的规则和算法设计。
#### AIGC
专注于非结构化数据的处理,如文本、图像、音频和视频,旨在创造出新颖的内容。其核心在于利用机器学习和深度学习技术自动生成具有创意和艺术性的作品。
---
### 技术路径与系统设计
#### 传统编程
依赖于程序员手动编写代码,依据确定的逻辑规则。特征选择和算法设计是关键步骤,常用的工具有决策树、支持向量机、贝叶斯分类器等。
#### AIGC
利用深度神经网络,特别是生成模型如GANs(生成对抗网络)、Transformer模型等,通过大量数据训练来自动学习并生成内容。这些模型能够自我优化以提高输出的质量和创造性。
---
### 应用场景
#### 传统编程
广泛应用于企业级应用、网页开发、系统软件、嵌入式系统等,强调功能的稳定性、效率和安全性。
#### AIGC
在创意产业、媒体、广告、个性化内容推荐、教育等领域崭露头角,提供个性化内容创作、辅助设计、自动化编辑等功能。
---
### 数据需求
#### 传统编程
虽然某些应用也需要大数据支持,但许多系统可以在有限数据集上表现出色,特别是那些基于规则和明确逻辑的任务。
#### AIGC
高度依赖大规模高质量数据进行训练,尤其是在自然语言处理、图像识别等领域,数据的多样性和质量直接影响生成内容的逼真度和创新性。
---
### 创新与影响
#### 传统编程
是信息技术的基础,支撑了数字化转型的早期阶段,但创新速度受限于人力和时间成本。
#### AIGC
正在推动新一轮的创新浪潮,通过自动化内容创作,不仅提高了效率,还开辟了前所未有的创意空间,对软件开发、内容创作等行业产生深远影响。
---
### 综上所述
传统编程与AIGC各有千秋,传统编程在精确控制和逻辑处理方面依旧重要,而AIGC则在创造性和个性化内容生成上展现出巨大潜力。两者在实际应用中往往是相辅相成的关系。随着技术的不断进步,未来可能会看到更多结合两者优势的新技术和应用模式出现。
---
### AIGC
基于LLM(Large Language Model)大模型
#### 那些传统编程可以被LLM取代
prompt编程给LLM下指示
---
### 正文
我们来通过传统编程和AIGC两种方式来进行爬取数据(通过node爬取豆瓣的数据):
#### 传统编程
1. **爬虫 Crawl**
- 发送一个HTTP请求 --> url --> GET --> `https://movie.douban.com/chart`
- 响应 html 字符串
- 解析html字符串,如果可以像css选择器一样,拿到了电影列表
- 最后将所有的电影对象组成数组,以json数组的方式返回 --> Done
2. **node 爬虫 后端功能**
- npm init -y 初始化为后端项目
- package.json 项目描述文件
- npm i 安装第三方包
- require
- main.js 入口文件
- 编排编程
#### 步骤
1. **创建index.js** 并在终端输入 `npm init -y` 将其初始化为后端项目,此时会多出一个json文件
---
### 结论
AIGC与传统编程各有优势,在未来的发展中可能会有更多结合两者优点的新技术和应用模式出现。
在使用 npm 命令进行项目依赖管理时,我们可以选择安装第三方库来增强我们项目的功能。例如:
1. 安装 `request` 库,用于发送 HTTP 请求:
```bash
npm i request
```
2. 安装 `request-promise` 库,提供一个更简洁的方式来处理请求:
```bash
npm i request-promise
```
3. 安装 `cheerio` 库,用于简化 HTML 解析操作,与 jQuery 类似但更加轻量级:
```bash
npm i cheerio
```
在安装完成后,我们可以查看 `json` 文件中的依赖项信息。这些信息反映了当前项目中使用的所有依赖包及其版本,这对于后续的更新和维护非常有帮助。

以下是对您提供的代码进行的改写,使其结构更清晰,并增加了适当的注释:
```javascript
// 引入依赖库
const request = require('request-promise') // 请求库
const cheerio = require('cheerio') // 将HTML str变成内存中DOM对象
const fs = require('fs') // 文件系统操作模块
const util = require('util')
// 定义变量
let movies = [] // 电影信息数组
let basicUrl = 'https://movie.douban.com/top250' // 豆瓣电影Top250的基础URL
let once = function (cb) {
let active = false
if (!active) { // 控制console.log只打印一次提示信息
cb()
active = true
}
}
// 获取单部电影的信息
function getMovieInfo (node) {
let $ = cheerio.load(node)
let titles = $('.info .hd span')
titles = [].map.call(titles, t => $(t).text())
let bd = $('.info .bd') // 找到满足一个类名为"info"的元素内部的、类名为"bd"的元素
let info = bd.find('p').text()
let score = bd.find('.star .rating_num').text()
return { titles, info, score }
}
// 获取页面信息,返回包含所有电影信息的列表
async function getPage (url, num) {
try {
const html = await request({
url
})
console.log('连接成功!', `正在爬取第${num+1}页数据`)
let $ = cheerio.load(html)
let movieNodes = $('#content .article .grid_view').find('.item')
return [].map.call(movieNodes, node => getMovieInfo(node))
} catch (error) {
console.error('获取页面信息失败!', error)
}
}
// 主函数,负责循环抓取多页数据
async function main () {
let count = 25
let list = []
for (let i = 0 ; i < count ; i++) { // 遍历前25页(每页25部电影,共625部)
let url = basicUrl + `?start=${25*i}`
try {
const movieList = await getPage(url, i)
list.push(...movieList)
} catch (error) {
console.error('获取第' + (i+1) + '页数据失败!', error)
}
}
console.log(list.length) // 输出最终抓取的电影数量
fs.writeFile('./output.json', JSON.stringify(list), 'utf-8', () => { // 将电影列表转换为JSON字符串并保存到名为output.json的文件中
console.log('生成json文件成功!')
})
}
main() // 执行main函数
```
### 解释
1. **依赖库**:首先引入了 `request-promise`、`cheerio` 和 `fs` 模块,以及 `util`。
2. **变量定义**:
- `movies` 存储电影信息。
- `basicUrl` 是豆瓣电影Top250的URL。
- `once` 函数确保控制 console.log 只打印一次提示信息。
3. **获取单部电影的信息**:函数 `getMovieInfo` 使用 cheerio 解析 HTML,提取电影标题、简介和评分,并以对象形式返回这些信息。
4. **获取页面信息**:异步函数 `getPage` 接收一个 URL 和页码作为参数,发送 HTTP 请求并解析 HTML,然后调用 `getMovieInfo` 函数提取每部电影的信息,并将结果合并到最终列表中。
5. **主函数**:
- 处理前25页数据,遍历每一页获取信息。
- 使用 `fs.writeFile` 将最终的电影列表转换为 JSON 字符串并保存到文件。
- 打印最终抓取的电影数量。
6. **执行 main 函数**:调用 `main()` 来启动整个抓取过程。


AIGC:
通过 Colaboratory (colab.research.google.com/?pli=1#sidebar=1) 新建笔记本。
要使用BeautifulSoup4进行网页解析,首先需要通过`pip`安装该库:
```bash
!pip install beautifulsoup4
```
这将确保你拥有最新版本的BeautifulSoup4,并将其安装到你的Python环境中。

3. 点击运行

再新建一个代码
引入所需库:
首先,通过`import requests`引入了`requests`库,用于发送HTTP请求。
接着,通过`from bs4 import BeautifulSoup`引入`BeautifulSoup`库,用于解析HTML文档,提取所需数据。
定义函数`fetch_movie_list(url)`:
这个函数接受一个URL参数,目的是获取并解析该URL指向的网页中的电影列表信息。
函数内部首先定义了一个HTTP请求头部(headers),模拟了一个常见的浏览器用户代理字符串,以便让服务器认为请求来自于一个正常的浏览器,增加请求成功的概率。
使用`requests.get(url, headers=headers)`发送GET请求到指定的URL,并存储响应到`response`变量中。
判断响应状态码是否为200,如果是,则说明请求成功;否则打印错误信息。
```python
if response.status_code == 200:
```
若请求成功,使用`BeautifulSoup`解析响应的HTML文本内容,选择器`'#wrapper #content .article .item'`被用来定位到电影列表项。
接下来,代码使用列表推导式和切片操作,提取前两个电影项的美化后(prettify)的HTML字符串,并拼接成一个大的字符串`all_movies_text`。
```python
all_movies_text = ''.join([movie.prettify() for movie in movies[:2]])
```
最终,函数返回这个包含前两个电影项信息的字符串:
```python
def fetch_movie_list(url):
# 设置HTTP 请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0'
}
# js有什么区别 js是异步 python 同步
response = requests.get(url, headers=headers)
# 状态码 成功
if response.status_code == 200:
# 内存中的dom对象
soup = BeautifulSoup(response.text, 'html.parser')
movies = soup.select('#wrapper #content .article .item')
# python 不是完全面向对象的,而更年轻的js 是完全面向对象
# 2.3123.foFixed(2) '123'.length
# 突兀
# print(len(movies))
# 字符串
# 人生苦短 我用python
all_movies_text = ''.join([movie.prettify() for movie in movies[:2]])
# print(all_movies_text)
return all_movies_text
else:
print("Failed to retrieve content ")
```
调用函数并打印结果:
定义了一个变量`url`,其值为豆瓣电影排行榜的URL。
调用`fetch_movie_list(url)`函数,将上述URL传入,获取电影列表信息,并将结果存储在`movies`变量中。
最后,打印出`movies`变量的内容,即前两个电影的HTML片段信息。
```python
url = 'https://movie.douban.com/chart'
movies = fetch_movie_list(url)
print(movies)
```
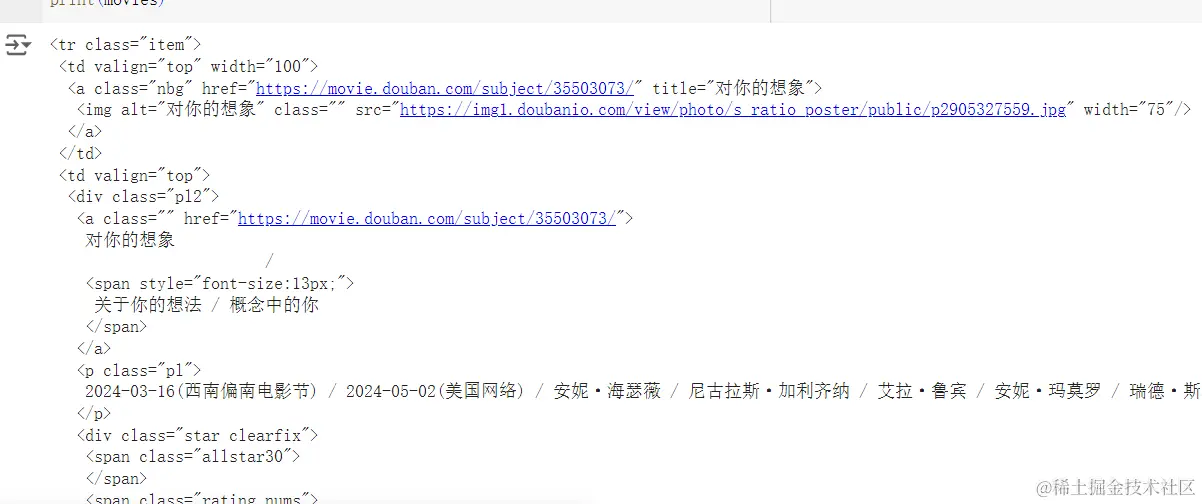
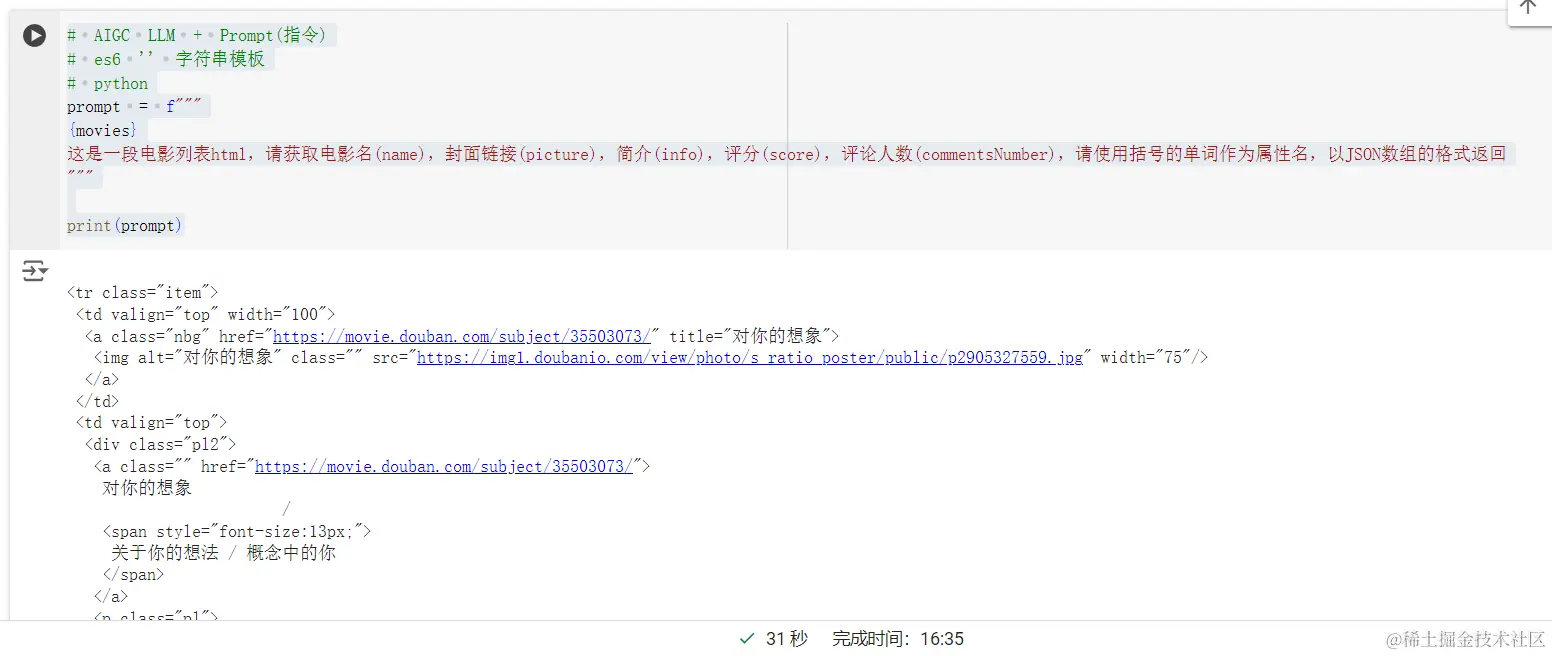
以下是改写后的文字:
新建一个代码文件,通过`prompt`变量定义为一个格式化的字符串,其中包含之前通过网络爬虫抓取到的电影列表HTML内容(存储在变量`movies`中)。这段HTML内容被嵌入到一个模板字符串中,该模板指导接下来的处理任务:从这段HTML中提取特定的电影信息。
# AIGC LLM + Prompt(指令)
# es6 '' 字符串模板
# python
```python
prompt = f"""
{movies}
这是一段电影列表html,请获取电影名(name),封面链接(picture),简介(info),评分(score),评论人数(commentsNumber),请使用括号的单词作为属性名,以JSON数组的格式返回
"""
print(prompt)
```
这段代码将打印出一个模板字符串,该字符串包含了要提取的电影信息,并且格式化为json。
在Python中,你可以通过以下步骤来创建一个新的代码片段,并使用`dashscope`库来调用阿里云开发的通义千问模型:
1. 安装`dashscope`库。运行以下命令:
```
pip install dashscope
```
2. 创建一个新的Python脚本文件(例如,名为`example_script.py`),并将其内容如下:
```python
import dashscope
# 初始化dashscope API
ds = dashscope.Api("your_api_key")
# 调用通义千问模型的示例代码
response = ds.text_generation('你好,阿里云!')
print(response)
```
在这个例子中,你需要将`"your_api_key"`替换为实际的API密钥。
3. 运行脚本:
```
python example_script.py
```
这个脚本首先初始化了`dashscope`API,并调用了通义千问模型生成了一个文本响应。根据你的实际情况,你可能需要修改代码以适应不同的需求。
为了在Python中使用DashScope,您需要首先创建一个新的代码文件。之后导入所需的库并设置API密钥。
### 步骤1:创建新的代码文件
新建一个名为`dashscope_script.py`的文件。
### 步骤2:导入DashScope库
```python
import dashscope
```
### 步骤3:设置API密钥
在使用DashScope之前,需要设置其API密钥。可以按照以下步骤操作:
1. 进入DashScope网站:`dashscope.aliyun.com/`
2. 登录到您的账号。
3. 点击“立即开通”。
获取到API密钥后,将其赋值给`dashscope.api_key`变量。
### 步骤4:将密钥赋值
```python
dashscope.api_key = 'sk-xxx'
```
这样就成功设置了DashScope的API密钥。现在您可以开始使用DashScope API了。
开通后回到首页,点控制台
点击API-KEY管理

创建新的API-KEY,记得保存!
13. 定义函数 `call_qwen_with_prompt()`:使用给定的 prompt 调用 Qwen 模型进行生成内容,创建了一个消息列表,其中包含一个字典。这个字典定义了消息的角色和内容(由外部变量 `prompt` 提供的文本)。这是向 Qwen 模型发起请求时所需的主要输入。通过调用 `dashscope.Generation.call()` 方法并指定模型类型为 `qwen_turbo`,以及将之前构建的消息列表作为输入,并设置了 `result_messages` 参数,并打印响应。
```python
def call_qwen_with_prompt():
messages = [
{
'role':'user',
'content': prompt
}
]
response = dashscope.Generation.call(
dashscope.Generation.Models.qwen_turbo,
messages=messages,
result_messages='message'
)
print(response)
```
调用函数:
```python
call_qwen_with_prompt()
```

在这个数字化时代,AI已经深深融入我们的生活和工作中。而最近,一项新兴的技术——AIGC(人工智能生成内容)正以迅猛之势向前发展,它代表着技术革新的前沿。作为开发者,你们不仅仅是编写代码的人,更是塑造未来世界的先驱。
拥抱AIGC意味着打开了通往无限创意与高效生产的门户。这不仅是对新技术的掌握和运用,更是一种对未来浪潮的把握。让自己的事业站在这场技术革命的最前线吧!
让我们一起见证并参与这场由AIGC引领的创意与技术革命!