AIGC下的编程:用爬虫爬取豆瓣电影中的信息
前言
何为编程?首先编程一定是现有一个目的(需求),根据需求做编程,我们想通过编程来解决世界上各种各样的问题。那么在传统意义上的编程,我们需要有扎实的编程基础(计算机网络、计算机组成原理...)等等相关理论知识,其次将大问题化小,不断细分我们的任务,分析我们要解决的问题如何解决,就像做算法题一样,可以先想出伪代码,什么语言都不重要,首先要有思想,有逻辑,不同的语言只是语法不同而已。最后我们将每一个功能模块化,封装、复用,这样有利于代码的可读性和可维护性。
2024年我认为我们应当好好把握AI元年给我们带来的红利,我们可以基于LLM大模型去做很多我们曾经想都不敢想的事情,在这样一个背景下,就出现了大量的prompt engineer。我们只需要给我们的大模型下指令,告诉他我们想做一件什么事情,这个事情大模型非常擅长,专业的事情交给专业的人去做,我们不再需要一味的学习各种API然后不断学习不断的忘记。
接下来我通过用爬虫做豆瓣电影中信息提取这么一个案例展开说说,传统编程到AIGC下的转变。movie.douban.com/chart 豆瓣电影的网址
正文
传统意义下的编程方式
使用 `request-promise`、`cheerio`、`fs` 和 `util` 等模块进行网页爬取并将数据保存为 JSON 文件的代码。通过遍历豆瓣电影 Top250 页面,获取电影信息并保存到数组中,最后将数据写入 JSON 文件。
具体来说(秉承他有我拿(爬虫)思想)
首先发生一个 HTTP 请求,用 url 发生一个 GET 请求 url:movie.douban.com/chart
响应的是 HTML (字符串)
解析 HTML 字符串,可以像 css 选择器一样,拿到电影列表
最后将所有的电影对象组成数组,以 json 数组的方式返回,爬虫结束
我们需要安装 node 环境,并下载相关的包以及导入相关模块
通过 npm init -y 初始化文件夹为后端项目,获得 package.json 项目描述文件
通过 npm i request-import 安装 request-import 模块到项目中。
通过 npm i cheerio 安装 cheerio 模块到项目中。
request-promise: 一个基于 request 的 Promise 封装库,用于发送 HTTP 请求。
cheerio: 一个 Node.js 库,用于方便地处理 HTML 文档,提供类似 jQuery 的 API。
当函数超过一定行数时可以模块化划分为几个子函数,有利于代码的可读性和调试。(封装、复用)
通过 css 子选择器 #content .article .grid_view .item 逐层找到电影项。
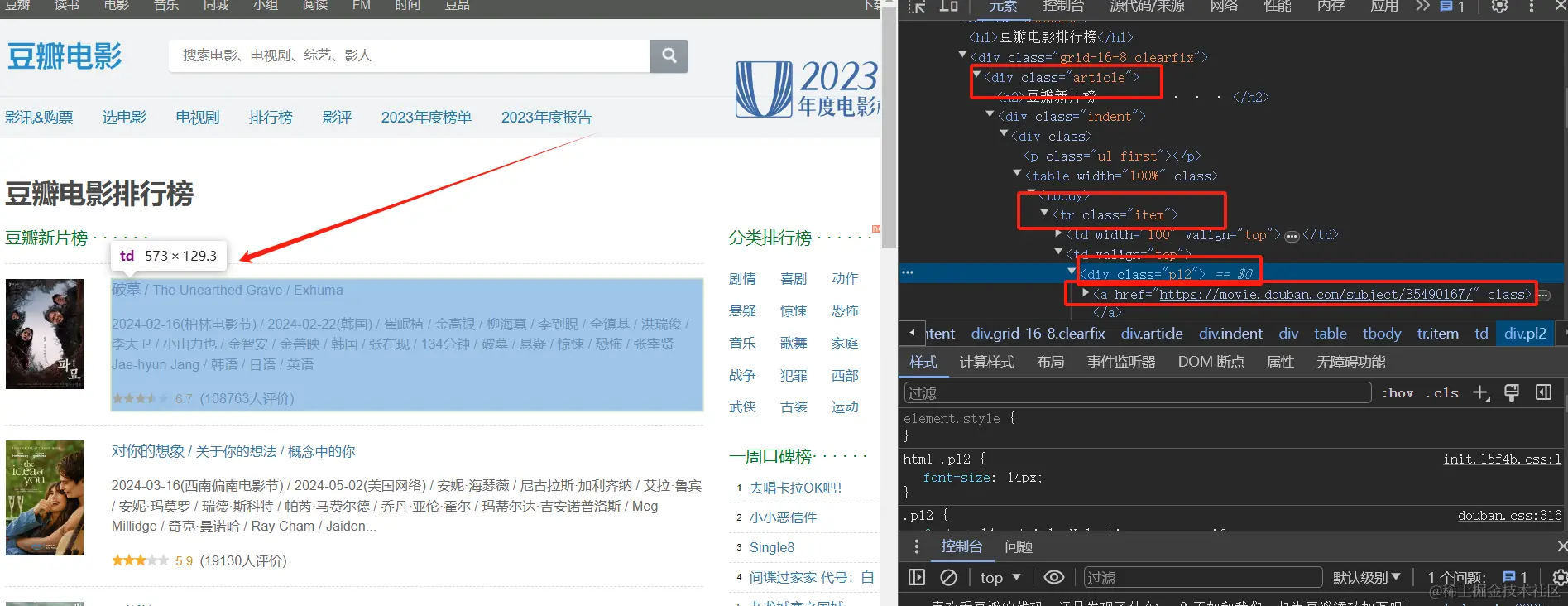
实现代码
```javascript
let request = require('request-promise');
let cheerio = require('cheerio');
let fs = require('fs');
const util = require('util');
let movies = [];
let basicUrl = 'https://movie.douban.com/top250';
let once = function (cb) {
let active = false;
if (!active) {
cb();
active = true;
}
};
function log(item) {
once(() => {
console.log(item);
});
}
function getMovieInfo(node) {
let $ = cheerio.load(node);
let titles = $('.info .hd span');
titles = ([]).map(t => $(t).text()).toArray();
let bd = $('.info .bd');
let info = bd.find('p').text();
let score = bd.find('.star .rating_num').text();
return { titles, info, score };
}
async function getPage(url, num) {
let html = await request({
url
});
console.log(`连接成功!正在爬取第${num + 1}页数据`);
let $ = cheerio.load(html);
let movieNodes = $('#content .article .grid_view').find('.item');
let movieList = ([]).map(node => getMovieInfo(node)).toArray();
return movieList;
}
async function main() {
const count = 25;
let list = [];
for (let i = 0; i < count; i++) {
let url = basicUrl + `?start=${i * 25}`;
list.push(...await getPage(url, i));
}
console.log(list.length);
fs.writeFile('./output.json', JSON.stringify(list), 'utf-8', () => {
console.log('生成json文件成功!');
});
}
main();
```
这个代码片段实现了一个从豆瓣电影Top250页面爬取数据并保存到JSON文件中的过程。它使用了`request-promise`进行网络请求,`cheerio`用于解析HTML内容,以及`fs`包来处理文件操作。通过递归调用`getPage`函数和`main`函数,它可以逐页获取电影信息,并将其存储在数组中最后保存到JSON文件中。
实际上,传统意义上的编程在这个话题中并不是我们的主题,因此请看下文如何进行AIGC的应用。
随着技术的发展,AIGC(人工智能生成内容)在一些领域展现出了强大的能力。例如,在自动化代码生成方面,它能简化重复性、模式化的任务。例如爬虫的例子就展示了通过给LLM做一些prompt就可以实现的功能。
通义 (aliyun.com)
只需告诉他一些指令,如“请帮我设计一个简单的爬虫程序,使用Node.js环境。目标是获取豆瓣电影Top榜的数据。首先,程序需要向 'movie.douban.com/chart' 发送GET请求,然后解析返回的HTML,提取出每个电影的标题和评分。最后,将这些信息整理成JSON格式输出。请确保包含必要的错误处理。”
为了帮助您实现这个需求,我将提供一个简单的Node.js爬虫程序示例代码:
```bash
1npm install axios cheerio
2const axios = require('axios');
3const cheerio = require('cheerio');
4async function fetchDoubanTopMovies() {
5 try {
6 const response = await axios.get('https://movie.douban.com/chart');
7 if (response.status !== 200) {
8 throw new Error(`请求失败,状态码:${response.status}`);
9 }
10 const html = response.data;
11 const $ = cheerio.load(html);
12 const movies = [];
13 $('div.item').each((index, element) => {
14 const title = $(element).find('.title a').text().trim();
15 const rating = $(element).find('.rating_num').text().trim();
16 if (title && rating) {
17 movies.push({
18 title: title,
19 rating: parseFloat(rating)
20 });
21 }
22 });
23 return JSON.stringify(movies, null, 4);
24 } catch (error) {
25 console.error('抓取过程中发生错误:', error);
26 return null;
27 }
28}
fetchDoubanTopMovies()
.then(data => {
if (data) {
console.log('获取到的电影数据:', data);
} else {
console.log('未能成功获取数据');
}
})
.catch(error => console.error('程序执行时出现错误:', error));
```
这段代码首先发送一个GET请求到豆瓣电影Top榜的页面,然后使用`cheerio`来解析返回的HTML。
它查找所有具有`.item`类的div元素(通常这些元素包含了每部电影的信息),并从中提取电影的标题和评分。
请注意,网页结构可能会随时间改变,因此如果该代码在未来失效,可能需要根据新的HTML结构进行调整。
最后,程序将提取到的电影信息整理成JSON格式并输出到控制台。同时,代码中也包含了基本的错误处理逻辑,以应对网络请求失败或其他潜在问题。
这样他就自动帮我把需要的程序给完成了。
又或者我们给他一些其他的提示,例如提供一个HTML代码以及一些提示让他帮你完成一些功能:
```bash
2024-03-16(西南偏南电影节) / 2024-05-02(美国网络) / 安妮·海瑟薇 / 尼古拉斯·加利齐纳 / 艾拉·鲁宾 / 安妮·玛莫罗 / 瑞德·斯科特 / 帕芮·马费尔德 / 乔丹·亚伦·霍尔 / 玛蒂尔达·吉安诺普洛斯 / Meg Millidge / 奇克·曼诺哈 / Ray Cham / Jaiden...
(19123人评价)
```
这是电影html,获取电影名(name), 封面链接(picture), 简介(info), 评分(score)以及评论人数(commentsNumber),以JSON格式返回。
他将会返回:
```json
{
"name": "对你的想象",
"picture": "https://img1.doubanio.com/view/photo/s_ratio_poster/public/p2905327559.webp",
"info": "2024-03-16(西南偏南电影节) / 2024-05-02(美国网络) / 安妮·海瑟薇 / 尼古拉斯·加利齐纳 / 艾拉·鲁宾 / 安妮·玛莫罗 / 瑞德·斯科特 / 帕芮·马费尔德 / 乔丹·亚伦·霍尔 / 玛蒂尔达·吉安诺普洛斯 / Meg Millidge / 奇克·曼诺哈 / Ray Cham / Jaiden...",
"score": "5.9",
"commentsNumber": "19123人"
}
```
AIGC作为一种新兴技术,正在逐渐改变我们的生活和工作方式。它展现出了强大的创造力和高效性,能够生成丰富多样的内容。虽然它对传统编程方式带来了一定的冲击,但两者也可以相互结合,发挥各自的优势。AIGC为我们带来了新的机遇和挑战,我们需要积极适应并探索其应用,以更好地推动科技的进步和发展。
拥抱AI,努力为中国互联网发展贡献自己的一份力量,结合自己的专业,实现更高效率的开发方式。