深度学习如何入门?
深度学习是一种强大的机器学习方法,广泛应用于各个领域。如果你是新手,想要入门深度学习,请参考以下步骤和资源:
### 1. 学习基本概念
在开始深度学习之前,你需要对一些基本概念有所了解。
- **神经网络**:它从信息处理的角度抽象人脑的神经元网络,建立某种简单模型,通过不同的连接方式组成各种网络。神经网络是一种运算模型,由大量神经元之间相互联接构成。
- **神经元**:神经元模型是一个包含输入、输出与计算功能的模型。
- **前向传播和反向传播**:这是神经网络的基本运行方式,前向传播用于计算输出,反向传播用于更新网络参数。
- **激活函数**:激活函数决定神经元的输出。学习不同的激活函数及其作用。
- **损失函数**:衡量模型的预测与实际结果之间的差异。了解不同类型的损失函数及其适用场景。
- **优化算法**:用于更新神经网络的参数以最小化损失函数。掌握常见的优化算法,如随机梯度下降法(SGD)和Adam。
### 2. 学习编程和数学基础
深度学习需要一定的编程和数学基础:
- **编程语言**:Python是深度学习的主要编程语言。学习 Python 的基本语法和常用库,如 NumPy、Pandas与Matplotlib。
- **线性代数**:了解线性代数的基本概念对于理解深度学习模型至关重要,但要求不高,通常本科及以上学生具备基础。
- **概率与统计**:概率和统计是深度学习中的一些概念和技术的基础。掌握基本的概率和统计知识有助于理解深度学习模型的工作原理。
### 3. 学习深度学习框架
深度学习框架可以让你更轻松地构建、训练和部署深度学习模型:
- **TensorFlow2**: 由 Google 开发的开源框架,简单且模块化较好,适合新手。在工业界中,TensorFlow 是非常重要的模型在线部署工具,但目前支持 Pytorch 的企业较多。
- **PyTorch**: 由 Facebook 开发的开源框架,前沿算法多为 PyTorch 版本。对于高校学生或研究人员推荐学习此框架,相比 TensorFlow 更易于调试。
选择一个深度学习框架并学习其基本用法和特性。官方文档和在线教程是学习的好资源。
### 4. 学习经典模型和案例
在入门深度学习后,可以开始学习一些经典的深度学习模型和案例:
- **卷积神经网络 (CNN)**:常用于图像识别和计算机视觉任务的常用模型,是一种专门处理具有类似网格结构的数据的神经网络。了解 CNN 的工作原理,并尝试在实际问题中应用它。
- **循环神经网络 (RNN)**:用于序列数据建模和自然语言处理任务的常用模型。
- **生成对抗网络 (GAN)**:用于生成新的数据样本的模型,是深度学习领域的一个热点方向。理解 GAN 的基本概念及其工作原理。
- **Transformer**: 用于自然语言处理任务,如机器翻译和文本生成。
### 5. 深度学习在 MNIST 手写数字识别上的应用
为了帮助你入门深度学习,我们将通过深度学习在 MNIST 手写数字识别上的应用带大家入门。MNIST 是一个著名的手写数字数据集,由 784 维特征向量(灰度图)组成。
#### 分步骤介绍:
1. **预处理和加载数据**:将 MNIST 数据集加载到你的深度学习框架中。
2. **构建模型结构**:使用 TensorFlow 或 PyTorch 构建卷积神经网络,用于识别手写数字。确保理解卷积层、池化层、全连接层以及它们的作用。
3. **训练和优化模型**:
- 定义损失函数(例如交叉熵),并选择合适的优化算法(如随机梯度下降法或 Adam)来最小化损失。
- 使用批量随机采样进行训练,确保每个样本被采样多次以减少波动性。
4. **评估模型性能**:使用测试集验证模型在新数据上的表现,并计算准确率、召回率等指标。
通过以上步骤,你将能够构建一个基本的深度学习模型来识别手写数字。这一过程不仅有助于加深对深度学习的理解,还提供了实践和应用的机会。

在这里,我们首先定义一个核心概念:**学习**。根据这个定义,我们可以进一步细分出**输入**和**输出**两个方面。
**输入**是指已经存在的信息或数据。这些信息可能是已知的事实、经验、观察结果等,它们是学习过程的基础。
**输出**则是由输入所获得的认知结果或知识。这部分可以包括理解、判断、推理以及应用这些信息来解决具体问题的能力。
最后,我们将一个认知过程定义为“学习”,这个过程从已经存在的信息出发,通过计算、判断和推理等活动,最终达到新的认知结果。
这种分类有助于我们更好地理解和分析认知活动,并进一步探索人类和智能系统如何通过学习从外部环境获取知识。

要让机器也能进行学习,学术界提出了"神经网络"的概念。人脑中负责活动的基本单元是神经元,这些神经元互相连接成一个被称为神经网络的庞大结构。由此,学术界模仿人脑“神经网络”建立了一个人工神经网络(ANN),我们通常也简称为神经网络。
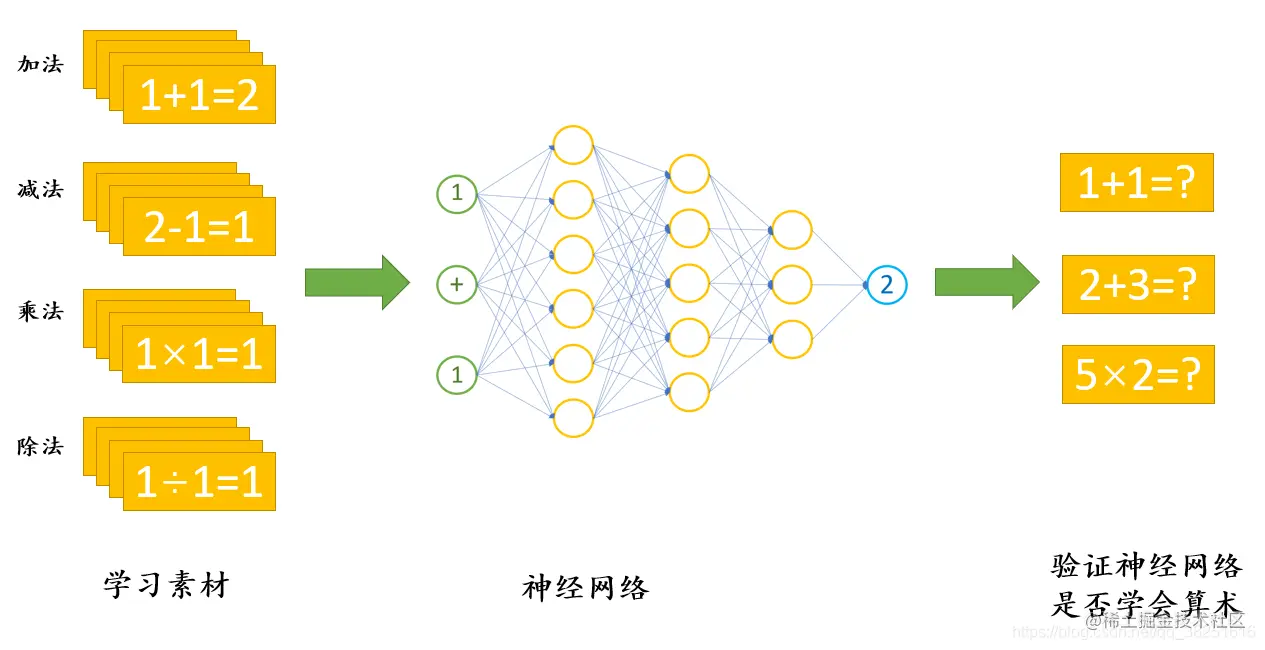
将1+1=2用神经网络可以表示为如下结构。
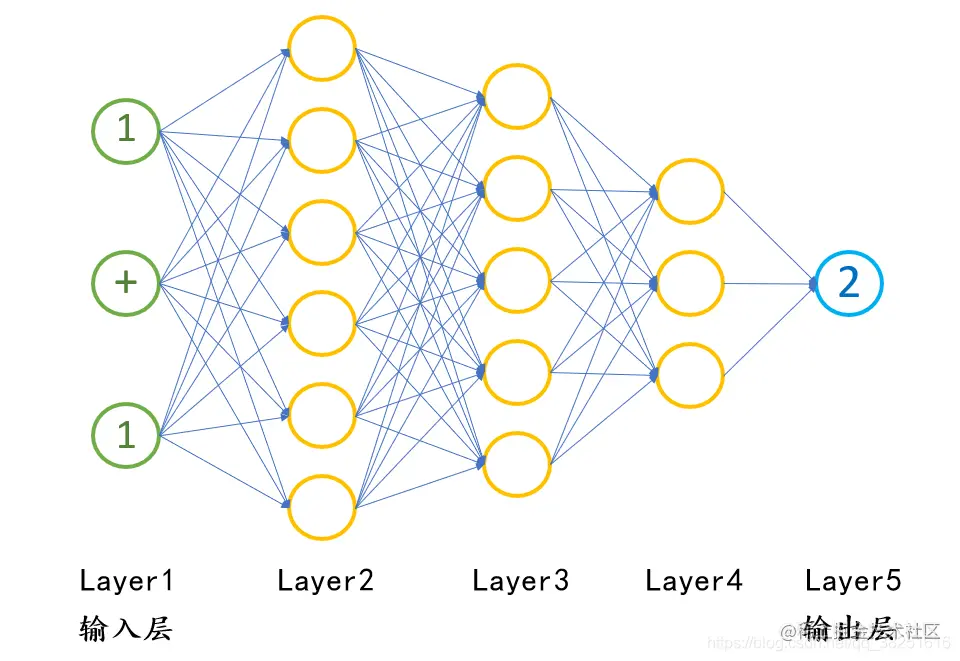
在深度学习的过程中,我们需要不断的对神经网络进行“训练”——将数据输入到它中,并告诉它应该输出什么。例如,当我们给它1+1的计算题时,它会自动得出结果2。同样地,当我们将1+2=3的算术题输入给神经网络后,经过多次这样的训练,神经网络最终能够学会并解决所有类似的加法问题。
通过这个过程,我们让神经网络学会了如何执行基本的算术运算。深度学习就是指机器能够在没有明确编程的情况下,通过大量数据和算法自动提升自己的能力,从而实现复杂任务如识别图像或理解自然语言等。
# 深度学习在生活中的应用
深度学习已经在我们的日常生活中扮演着越来越重要的角色。从自动驾驶汽车到语音识别、自动机器翻译和即时视觉翻译(拍照翻译),再到目标识别等领域的应用都显示出了其强大的功能。
## 自动驾驶
- **手机上的小爱同学**:这款智能助手利用了深度学习技术,能够理解和响应用户的语音指令。
- **地铁口的人脸识别**:在公共场所进行的面部识别也是基于深度学习算法来实现的。
# 深度学习的应用实例
我们以MNIST手写数字数据集为例,进一步讲解深度学习的实现过程。假设我们手中有很多张手写的数字图片,任务是让机器“认识”这些图片上的数字,并告诉我们每一张图片上的数字是多少。
## 问题描述
- **目标识别**:我们需要训练一个模型来对输入的图像进行分类,从而预测出每一幅图中的数字。
- **数据集**:使用MNIST手写数字数据集,其中包含60,000张训练样本和10,000张测试样本。
## 模型构建
### 数据预处理
首先对图片进行预处理,包括图像归一化、灰度化和像素填充等步骤。然后将所有图片统一尺寸为28x28的灰度图。
### 特征提取
使用卷积神经网络(CNN)来提取手写数字的特征,通过多个卷积层和池化层进行特征抽象和压缩。
### 模型训练
采用反向传播算法训练模型。在训练过程中,会不断地调整权重以最小化损失函数,直到达到满意的预测准确度为止。
### 预测与评估
完成训练后,使用测试集对模型进行验证,计算其在测试集上的准确率和误差分布等指标。
# 结论
通过上述过程,我们可以看到深度学习是如何一步步地构建一个能够“认识”手写数字的分类器。这不仅展示了深度学习的强大能力,也为我们提供了一个全面理解深度学习实现过程的机会。
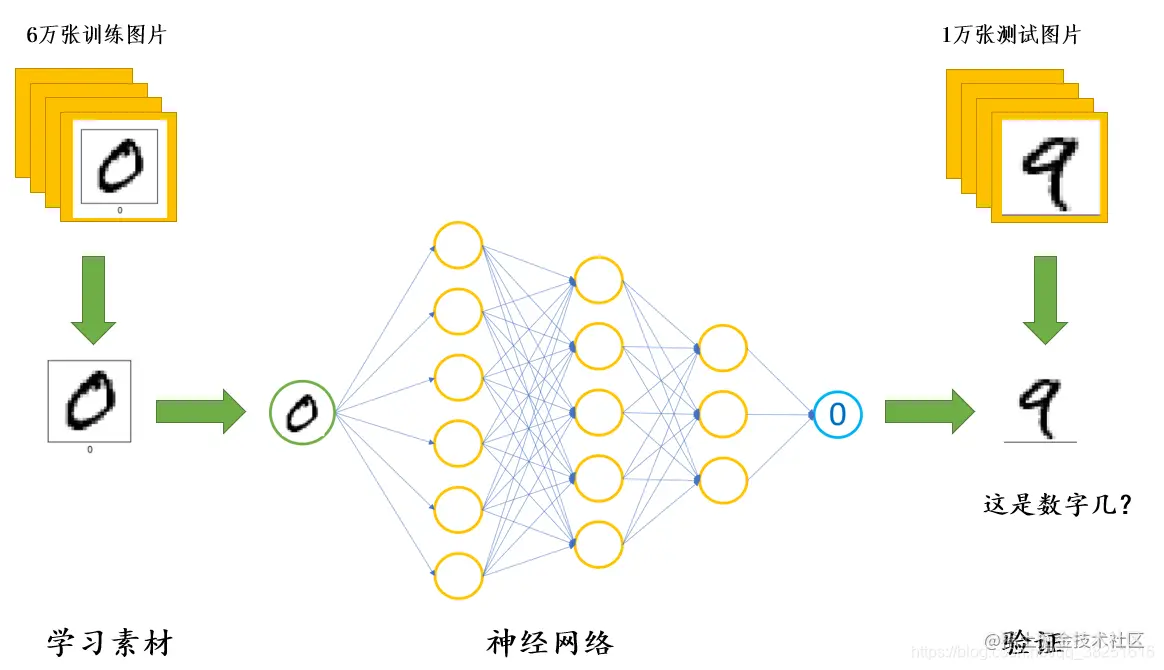
那么我们应该如何实现呢?总体的思路如下:
我们首先拿出六万张图片给机器进行学习(需要告诉机器每一幅图片上所写的数字是什么)。在学习完成后,再拿一万个“没见过”的机器没有见过的图片给它进行识别,让它告诉我们图片上所写的是哪一个数字。重复这个过程,直到机器可以认识手写的数字。
至此,完成便可实现手写数字识别这一效果。
二、实现过程
### 程序执行步骤:
#### ① 学习6万张图片上的数字
- 使用TensorFlow和Keras库加载MNIST数据集。
- 分别加载训练图片和标签,以及测试图片和标签。
```python
import tensorflow as tf
from tensorflow.keras import datasets, layers, models
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 输出数据形状
train_images.shape, test_images.shape
((60000, 28, 28), (10000, 28, 28))
```
#### ② 用1万张图片测试机器的学习效果(这1万张不参与①的训练)
- 训练模型之前,先使用1万张未参与训练的数据集进行验证。
```python
# 打印数据形状
train_images.shape, test_images.shape
((60000, 28, 28), (10000, 28, 28))
```
#### ③ 重复执行步骤①和步骤②
- 分别进行训练和验证,以确保模型准确。
### 使用的编译器
```python
# 编译器:Jupyter Notebook
# 图片可视化
import matplotlib.pyplot as plt
# 设置窗口大小为20*12单位英寸
plt.figure(figsize=(20, 12))
for i in range(20):
# 设置子图行数为5,列数为10,i+1表示第几个子图
plt.subplot(5, 10, i + 1)
# 去掉坐标轴刻度
plt.xticks([])
plt.yticks([])
# 显示图片
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 显示标签
plt.xlabel(train_labels[i])
plt.show()
```
### 环境配置
#### 语言环境:Python3.10.11
- 编译器:Jupyter Notebook
- 深度学习框架:TensorFlow 2.4.1
- 显卡(GPU):NVIDIA GeForce RTX 4070
### 相关教程
#### 深度学习环境配置教程
- 【新手入门深度学习 | 1-1:配置深度学习环境】
#### 基础资料库
- 【新手入门深度学习 | 目录】
- 📖《新手入门深度学习》
- 📖《深度学习100例》
- 🔥365天深度学习训练营🔥
### 代码详解
```python
# 加载数据集
(train_images, train_labels), (test_images, test_labels) = datasets.mnist.load_data()
# 打印数据形状
train_images.shape, test_images.shape
((60000, 28, 28), (10000, 28, 28))
```
- 分别加载训练图片和标签,以及测试图片和标签。
```python
# 打印数据形状
train_images.shape, test_images.shape
((60000, 28, 28), (10000, 28, 28))
```
- 打印训练图片和标签的形状。
#### 图片可视化
```python
# 设置窗口大小为20*12单位英寸
plt.figure(figsize=(20, 12))
for i in range(20):
# 设置子图行数为5,列数为10,i+1表示第几个子图
plt.subplot(5, 10, i + 1)
# 去掉坐标轴刻度
plt.xticks([])
plt.yticks([])
# 显示图片
plt.imshow(train_images[i], cmap=plt.cm.binary)
# 显示标签
plt.xlabel(train_labels[i])
plt.show()
```
- 使用matplotlib库可视化MNIST数据集中的手写数字,查看其形状和分布。

调整图片格式
需要将图片调整为特定格式程序才可以进行学习。
# 调整数据到我们需要的格式
train_images = train_images.reshape((60000, 28, 28, 1))
test_images = test_images.reshape((10000, 28, 28, 1))
输出数据shape
(train_images.shape: (60000, 28, 28, 1),
test_images.shape: (10000, 28, 28, 1),
train_labels.shape: (60000,),
test_labels.shape: (10000,))
(60000, 28, 28, 1):表示为:60000张28*28的灰度图片,最后一个数字为1时代表灰度图片;为3时代表彩色图片。
构建神经网络模型
我们将图片输入到网络,图片首先会将其数字化,紧接着通过卷积层提取图片上这个数字的特征,最后通过数字的特征判断这个数字是哪一个。结构图如下:
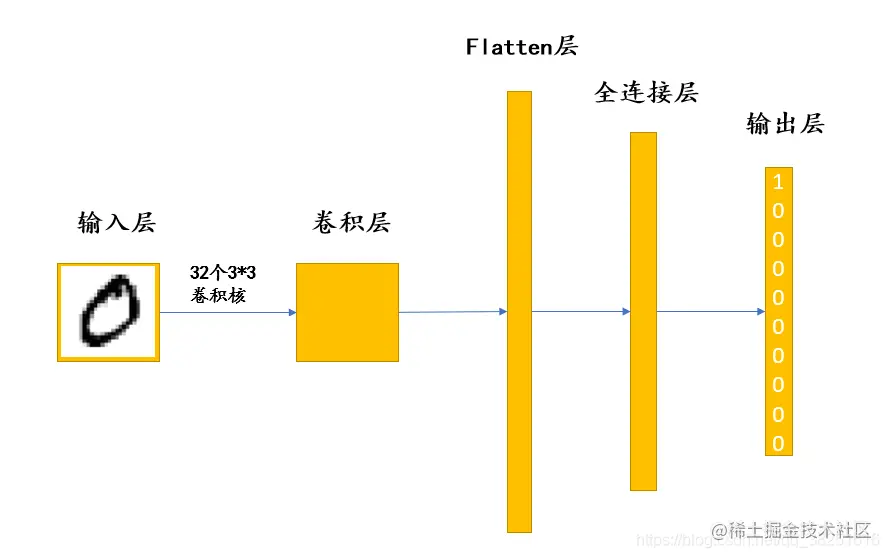
在上面的结构图中,向我们展示了五层结构。那么每一层具体是用来做什么的呢?
输入层:用于将数据输入到神经网络。
卷积层:使用卷积核提取图片特征,卷积核相当于一个小型的“特征提取器”。
Flatten层:将多维的输入一维化,常用在卷积层到全连接层的过渡。
全连接层:起到“特征提取器”的作用。
输出层:输出结果。
卷积核与全连接层从某些方面上讲都有提取特征的作用,但是所采用的方法是不同的。这部分为深度学习的核心内容,我将在第四部分(构建模型)重点向大家进行更详细深入的讲解。现在我们主要任务是跑通整个程序,从整体上了解一下深度学习是什么。
model = models.Sequential([
# 卷积层:提取图片特征
layers.Conv2D(32, (3, 3), input_shape=(28, 28, 1)),
# Flatten层:将二维图片压缩为一维形式
layers.Flatten(),
# 全连接层:将特征进行进一步压缩
layers.Dense(100),
# 输出层:输出结果
layers.Dense(10)
])
# 打印网络结构
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
flatten (Flatten) (None, 21632) 0
_________________________________________________________________
dense (Dense) (None, 100) 2163300
_________________________________________________________________
dense_1 (Dense) (None, 10) 1010
=================================================================
Total params: 2,164,630
Trainable params: 2,164,630
Non-trainable params: 0
_________________________________________________________________
在第三部分,我们需要设置模型的优化器、损失函数和评价函数。这里我们选择Adam作为优化器,SparseCategoricalCrossentropy作为损失函数,Accuracy作为评价指标。
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])
现在我们主要任务是跑通整个程序,从整体上了解一下深度学习是什么。
train_images :训练数据的图片
train_labels :训练图片对应的标签
epochs :训练轮数
validation_data:验证数据
history = model.fit(train_images, train_labels, epochs=3,
validation_data=(test_images, test_labels))
在第四部分,我们将进行预测。

在第一张测试集中图片对应的预测数组为:
```
[12.474585, 1.1173537, 21.654232, 16.206923, -10.989567,
17.235504, 19.404213, -22.553476, 13.221286, -10.19972]
```
该数组中的浮点数对应着0~9,最大的浮点数表示的数字是模型预测的结果。因此,第一张测试集中图片对应的神经网络预测结果为 **2**。
通过本次学习和实践,我们不仅对深度学习有了全面的认识,还了解到TensorFlow 2.0是一个强大的框架,能够帮助我们构建、训练并部署深度学习应用。此外,我们用MNIST数据集完成了手写数字的识别任务,这证明了在实际应用中如何使用模型进行图像分类和识别。
通过这次操作,我们不仅理解了深度学习的基本原理,还掌握了TensorFlow 2.0的具体实现方法,从而为未来可能的应用提供了宝贵的经验。