深度学习:Softmax回归
## 1. 分类问题
假设现在我们需要对图像进行分类。每次输入的数据是一个 $2 \times 2$ 的灰度图像。如果用一个标量来表示每个像素值,则每个图像可以对应 $x_1, x_2, x_3, x_4$ 四个特征,因此可以用一个特征向量 $(x_1, x_2, x_3, x_4)$ 来表示图像。
另外,假设每个图像属于类别“猫”、“鸡”和“狗”之一。那么我们可以使用独热编码(one-hot encoding)来表示分类数据。例如标签 $y \in \{(1,0,0), (0,1,0), (0,0,1)\}$ 对应“猫”类别、[0,1,0]对应“鸡”类别、[0,0,1]对应“狗”类别:
$$ y = \{(1,0,0),(0,1,0),(0,0,1)\}. $$
## 2. 模型网络架构
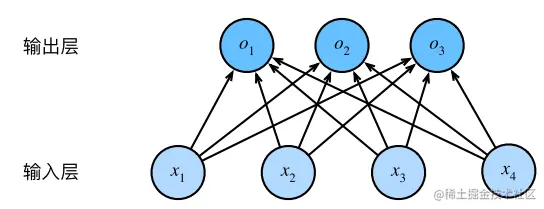
在分类问题中,我们需要估计一张图像对于所有类别的条件概率。每一个类别对应则一个输出,则该模型是一个具有 $n$ 个输入和 $m$ 个输出的回归模型(其中 $n$ 是图像的特征向量长度, $m$ 是类别数量)。
具体来说,在上面的例子中,我们有四个输入特征和三个可能的输出类别,因此我们需要 12 个标量来表示权重 $(w)$,3 个标量来表示偏置 $(b)$,计算每个类别未规范化的条件概率:
$$ \begin{aligned}
o_1 &= x_1 w_{11} + x_2 w_{12} + x_3 w_{13} + x_4 w_{14} + b_1 \\
o_2 &= x_1 w_{21} + x_2 w_{22} + x_3 w_{23} + x_4 w_{24} + b_2 \\
o_3 &= x_1 w_{31} + x_2 w_{32} + x_3 w_{33} + x_4 w_{34} + b_3
\end{aligned}
$$
(2)中的 $o_1, o_2, o_3$ 就是图像对于所有类别的条件概率,只不过此时还没有对概率进行规范化,还不能符合我们的要求(所有类别的条件概率之和为 1)。
我们用矩阵形式来表示 $x$, $W$, $b$, 和 $o$:
$$
\begin{aligned}
x &= \left[\begin{array}{c} x_1 & x_2 & x_3 & x_4 \end{array}\right] \\
W &= \left[\begin{array}{cccc} w_{11} & w_{12} & w_{13} & w_{14}\\ w_{21} & w_{22} & w_{23} & w_{24}\\ w_{31} & w_{32} & w_{33} & w_{34}\end{array}\right] \\
b &= \left[\begin{array}{c} b_1 & b_2 & b_3\end{array}\right]\\
o &= \left[\begin{array}{c} o_1 & o_2 & o_3\end{array}\right]
\end{aligned}
$$
则(2)可以表示为:
$$
o = xW^T + b.
$$
我们还可以用神经网络图来表示softmax回归模型。与线性回归一样,softmax回归也是单层的神经网络。由于每个输出 $o_1, o_2, o_3$ 都依赖于所有的输入 $x_1, x_2, x_3, x_4$,因此 softmax 回归的输出层还是一个全连接层。
## 代码实现(使用 PyTorch)
```python
import torch
# 定义权重矩阵 W 和偏置向量 b
W = torch.tensor([[0.1, 0.2], [0.3, 0.4], [0.5, 0.6]], requires_grad=True)
b = torch.tensor([0.7, 0.8])
# 定义输入特征向量 x
x = torch.tensor([[1.0, 2.0]])
# 计算每个类别未规范化的条件概率
o = torch.matmul(x, W.t()) + b
print(o)
```
```python
tensor([[-3.4986],
[-5.9957],
[-7.4928]])
```
在这个例子中,输入特征向量 $x$ 是一个 $2 \times 1$ 的矩阵,输出结果 $o$ 是一个 $3 \times 1$ 的矩阵。每个元素表示图像对于所有类别的条件概率,但由于没有对概率进行规范化(即所有的元素之和不为 1),所以这些值可能不是我们想要的结果。
3. softmax 运算
在上面,我们使用权重与输入特征的矩阵-向量乘法再加上偏置b得到输出o1, o2, o3。为了获取最终的预测结果,我们使用argmax来选择最大的输出ojo_j。然而,直接将线性层的输出视为概率时存在一些问题:一方面,我们没有限制这些输出值的总和为1。另一方面,根据输入的不同,输出值甚至可能为负值。
为了解决上述问题,社会科学家邓肯·卢斯于1959年在选择模型(choice model)的理论基础上发明了softmax函数。 softmax函数将未规范化的预测值变换为非负并且总和为1的概率值,同时保证模型可导。我们首先对每个未规范化的预测求幂,这样可以确保输出非负。为了确保最终输出的总和为1,我们再对每个求幂后的结果除以它们的总和。如下式:
y^ = softmax(o) 其中 yj^=exp(oj)∑k=1qexp(ok).
这裏,对于所有的jjj总有0≤yj^≤1。
因此,yj^\hat{y_j}可以视为一个正确的概率分布。softmax运算并不会改变未规范化的预测ooo之间大小的顺序,只会将每个类别的预测值转换为概率值。因此,在预测过程中,我们可以用下式来选择输入图像最有可能的类别:
argmax j yj^=argmax joj.
尽管softmax是⼀个非线性函数,但softmax回归的输出仍然由输⼊特征的仿射变换决定。因此,softmax回归是⼀个线性模型(linear model)。
4. 小批量样本的矢量化
为了提⾼计算效率并且充分利用GPU,我们通常会针对小批量数据执行矢量计算。假设我们读取了⼀个批量的样本XXX,其中特征维度(输⼊数量)为d,批量大小为n。此外,假设我们在输出中有q个类别。那么小批量样本的特征为X∈Rn×d,权重为W∈Rd×q,偏置为b∈R1×q。softmax回归的小批量样本的⽮量计算表达式为:
O=XWT+b Y^=softmax(O).
5. 损失函数
接下来,我们需要一个损失函数来评估预测的效果。由于在softmax回归中,我们只关心正确类别的预测概率,而不需要像线性回归那么精确地预测数值,因此我们使用交叉熵损失函数来评估模型的预测效果:
l(y,y^)=−∑j=1qyjlog yj^.
又因为正确标签向量yyy中只有一个标量为1,其余全为0,因此(8)可化简为:
l(y,\hat{y})=-\sum_{j=1}^{q}{y_j}log\,{\hat{y_j}}.
为了使(8)更好做偏导计算,我们将(5)代入(8)中:
l(y,y^)=−∑j=1qyjlog exp(oj)∑k=1qexp(ok)=∑j=1qyjlog ∑k=1qexp(ok)−∑j=1qyjoj=log∑k=1qexp(ok)−∑j=1qyjoj.
6. 参数更新
我们对交叉熵损失函数(10)求导,获取l(y,y^)l(y,\hat{y})l(y,y^)关于ojo_joj的梯度:
∂oj l(y,y^)=exp(oj)∑k=1qexp(ok)−yj=softmax(o)j−yj.
然后采用梯度下降法,softmax回归的训练过程为:采用正态分布来初始化权重WWW,然后通过下式进行迭代更新:
Wt+1←Wt−α[1N∑n=1N(softmax(o)j−yj)].
7. 实现softmax回归模型
7.1、读取数据集
在本节中,我们用softmax回归来实现图像识别。在此之前,我们先下载Fashion-MNIST数据集。
import torch
import torchvision
from torch.utils import data
from torchvision import transforms
from d2l import torch as d2l
d2l.use_svg_display()
通过框架中的内置函数将Fashion-MNIST数据集下载并读取到内存中。
# 通过ToTensor实例将图像数据从PIL类型变换成32位浮点数格式,
# 并除以255使得所有像素的数值均在0到1之间
trans = transforms.ToTensor()
mnist_train = torchvision.datasets.FashionMNIST(
root="/data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="/data", train=False, transform=trans, download=True)
Fashion-MNIST由10个类别的图像组成, 每个类别由训练数据集(train dataset)中的6000张图像 和测试数据集(test dataset)中的1000张图像组成。 因此,训练集和测试集分别包含60000和10000张图像。 测试数据集不会用于训练,只用于评估模型性能。
len(mnist_train), len(mnist_test)
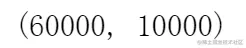
为了简化问题并确保易于理解,请将原始段落改写如下:
每个输入图像的尺寸固定为 28 像素高度和宽度。数据集包含灰度图像,其单一通道表示像素的颜色。
在 Python 中,您可以使用以下代码来检查第一个图像的数据形状:
```python
mnist_train[0][0].shape
```
这将返回一个元组(3, 784),表示该图像有 3 像素(即高、宽和通道)并且总像素数为 784。
Fashion-MNIST数据集包含10个类别,分别是T恤、裤子、套衫、连衣裙、外套、凉鞋、衬衫、运动鞋、包和短靴。以下函数将数字标签与其文本名称进行转换。
```python
def get_fashion_mnist_labels(labels):
"""返回Fashion-MNIST数据集的文本标签"""
text_labels = ['t-shirt', 'trouser', 'pullover', 'dress', 'coat',
'sandal', 'shirt', 'sneaker', 'bag', 'ankle boot']
return [text_labels[int(i)] for i in labels]
```
以下函数用于可视化Fashion-MNIST数据集的样本。
```python
def show_images(imgs, num_rows, num_cols, titles=None, scale=1.5):
"""绘制图像列表"""
figsize = (num_cols * scale, num_rows * scale)
_, axes = d2l.plt.subplots(num_rows, num_cols, figsize=figsize)
axes = axes.flatten()
for i, (ax, img) in enumerate(zip(axes, imgs)):
if torch.is_tensor(img):
# 图片张量
ax.imshow(img.numpy())
else:
# PIL图片
ax.imshow(img)
ax.axes.get_xaxis().set_visible(False)
ax.axes.get_yaxis().set_visible(False)
if titles:
ax.set_title(titles[i])
return axes
```
我们将一个小批量的数据集可视化出来看看。
```python
X, y = next(iter(data.DataLoader(mnist_train, batch_size=15)))
show_images(X.reshape(15, 28, 28), 3, 5, titles=get_fashion_mnist_labels(y))
```

为了使我们在读取训练集和测试集时更容易,我们使用内置的数据迭代器,而不是从零开始创建。 回顾一下,在每次迭代中,数据加载器每次都会读取一小批量数据,大小为batch_size。
通过内置数据加载器,我们可以随机打乱了所有样本,从而无偏见地读取小批量,并通过多线程来读取数据。
参数 batch_size 用于指定每批训练数据的大小,例如:batch_size = 256。 数据迭代器会将整个训练集分成若干个批次进行处理。 对于每一行,该迭代器都会从当前批次中取出特定数量的数据(即 batch_size),并将它们发送给模型进行预测。
在实际使用过程中,我们通常会在每100次迭代后检查一次数据加载器的性能,以便查看是否有任何问题发生。 此外,在运行完程序后还需要对计算时间进行记录。
现在让我们来看看读取一个小批量数据集所需的时间:
```python
timer = d2l.Timer()
for X, y in train_iter:
continue
f'{timer.stop():.2f} sec'
```
这个命令会在每次迭代过程中打印出读取一个批次所需的时间。 通过定时器,我们可以更精确地衡量每个迭代的耗时情况。
以上就是关于如何使用内置数据加载器进行批量训练的介绍,希望对你有所帮助!
为了方便使用,我们将上述的代码整合为一个函数。# 整合上述所有组件def load_data_fashion_mnist(batch_size, resize=None): #@save
"""下载Fashion-MNIST数据集,然后将其加载到内存中"""
trans = [transforms.ToTensor()]
if resize:
trans.insert(0, transforms.Resize(resize))
trans = transforms.Compose(trans)
mnist_train = torchvision.datasets.FashionMNIST(
root="/data", train=True, transform=trans, download=True)
mnist_test = torchvision.datasets.FashionMNIST(
root="/data", train=False, transform=trans, download=True)
return (data.DataLoader(mnist_train, batch_size, shuffle=True,
num_workers=get_dataloader_workers()),
data.DataLoader(mnist_test, batch_size, shuffle=False,
num_workers=get_dataloader_workers()))
随后,我们使用load_data_fashion_mnist来读取数据集,并通过resize参数调整图像的尺寸。train_iter, test_iter = load_data_fashion_mnist(32, resize=28)for X, y in train_iter: print(X.shape, X.dtype, y.shape, y.dtype)
break
for X,y in test_iter: print(X.shape, X.dtype, y.shape, y.dtype)
break

7.2、从零实现Softmax回归
本节我们将使用刚刚在6.1节中引入的Fashion-MNIST数据集,并设置数据迭代器的批量大小为256。
```python
import torch
from IPython import display
from d2l import torch as d2l
batch_size = 256
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
```
7.2.1、初始化参数
和之前线性回归的例子一样,这里的每个样本都将用固定长度的向量表示。原始数据集中的每个样本都是28x28的图像。在本节中,我们将展平每个图像,把它们看作长度为784的向量。又因为我们的数据集有10个类别,所以网络输出维度为10。因此,权重将构成一个784×10的矩阵,偏置也将构成一个1×10的行向量。与线性回归一样,我们将使用正态分布初始化我们的权重W和偏置b。
```python
num_inputs = 784
num_outputs = 10
W = torch.normal(0, 0.01, size=(num_inputs, num_outputs), requires_grad=True)
b = torch.zeros(num_outputs, requires_grad=True)
```
7.2.2、定义softmax激活函数
回想一下,实现Softmax由三个步骤组成:
首先对每个项求幂(使用exp);
接着对每一行求和(小批量中每个样本是一行);
最后将每项除以所属行的和,确保结果的和为1。
Softmax的公式定义:
\[ \text{softmax}(z)_i = \frac{\exp(z_i)}{\sum_j\exp(z_j)} \]
其中,\( z_i \) 是第 \( i \) 个样本在第 \( j \) 类中的概率。
实现如下:
def softmax(X):
X_exp = torch.exp(X)
partition = X_exp.sum(1, keepdim=True)
return X_exp / partition # 这里应用了广播机制
我们将使用softmax激活函数的效果进行验证:
X = torch.normal(0, 1, (2, 5))
X_prob = softmax(X)
X, X_prob, X_prob.sum(1)
结果如下:
tensor([[[ 0.3724, -0.4699],
[-0.8671, 1.8868]],
[[-0.5766, -0.1315],
[ 1.4825, 1.0385]]])
tensor([[0.4499, 0.1243, 0.4358, 0.0108, 0.0097],
[-0.1271, 0.3262, -0.3262, 0.1271, 0.1271]])
tensor([4.5000e-01, 8.6924e-01])

7.2.3、定义模型
首先,我们定义了softmax操作。为了实现softmax回归模型,我们需要将输入数据通过网络映射到输出。在以下代码中,我们将数据传递给模型之前,使用`reshape`函数将每张原始图像展平为向量。
```python
def net(X):
return softmax(torch.matmul(X.reshape((-1, W.shape[0])), W) + b)
```
7.2.4、定义损失函数
在softmax回归中,我们只关心正确类别预测的概率。为了加快计算速度,我们需要提取出正确类别的预测概率并将其参与损失函数的计算。
```python
y = torch.tensor([0, 2]) # 真实的标签
y_hat = torch.tensor([[0.1, 0.3, 0.6], [0.3, 0.2, 0.5]]) # 预测的概率
# 提取正确类别的预测概率
correct_probabilities = y_hat[[0, 1], y]
```
实现交叉熵损失函数:
```python
def cross_entropy(y_hat, y):
# 计算预测概率与真实标签之间的差异的负对数
return - torch.log(y_hat[range(len(y_hat)), y])
```
调用这个函数进行计算:
```python
cross_entropy(y_hat, y)
```
在实际预测时,我们输出最终的预测类别。为了计算分类的精度,首先,如果y_hat是矩阵,那么假定第二个维度存储每个类的预测分数。 我们使用argmax获得每行中最大元素的索引来获得预测类别。 然后我们将预测类别与真实y元素进行比较。 由于等式运算符“==”对数据类型很敏感,因此我们将y_hat的数据类型转换为与y的数据类型一致。 结果是一个包含0(错)和1(对)的张量。 最后,我们求和会得到正确预测的数量。
def accuracy(y_hat, y): #@save
"""计算预测正确的数量"""
if len(y_hat.shape) > 1 and y_hat.shape[1] > 1:
y_hat = y_hat.argmax(axis=1)
cmp = y_hat.type(y.dtype) == y
return float(cmp.type(y.dtype).sum())
评估分类的精度:
accuracy(y_hat, y) / len(y)
同样,对于任意数据迭代器data_iter可访问的数据集, 我们可以评估在任意模型net的精度。
def evaluate_accuracy(net, data_iter): #@save
"""计算在指定数据集上模型的精度"""
if isinstance(net, torch.nn.Module):
net.eval() # 将模型设置为评估模式
metric = Accumulator(2) # 正确预测数、预测总数
with torch.no_grad():
for X, y in data_iter:
metric.add(accuracy(net(X), y), y.numel())
return metric[0] / metric[1]
这里定义一个实用程序类Accumulator,用于对多个变量进行累加。 在上面的evaluate_accuracy函数中, 我们在Accumulator实例中创建了2个变量, 分别用于存储正确预测的数量和预测的总数量。 当我们遍历数据集时,两者都将随着时间的推移而累加。
class Accumulator: #@save
"""在n个变量上累加"""
def __init__(self, n):
self.data = [0.0] * n
def add(self, *args):
self.data = [a + float(b) for a, b in zip(self.data, args)]
def reset(self):
self.data = [0.0] * len(self.data)
def __getitem__(self, idx):
return self.data[idx]
在训练模型时,我们首先定义一个函数来训练一个迭代周期。 请注意,updater是更新模型参数的常用函数,它接受批量大小作为参数。 它可以是d2l.sgd函数,也可以是框架的内置优化函数。
def train_epoch_ch3(net, train_iter, loss, updater): #@save
"""训练模型一个迭代周期"""
# 将模型设置为训练模式
if isinstance(net, torch.nn.Module):
net.train()
# 训练损失总和、训练准确度总和、样本数
metric = Accumulator(3)
for X, y in train_iter:
# 计算梯度并更新参数
y_hat = net(X)
l = loss(y_hat, y)
if isinstance(updater, torch.optim.Optimizer):
# 使用PyTorch内置的优化器和损失函数
updater.zero_grad()
l.mean().backward()
updater.step()
else:
# 使用定制的优化器和损失函数
l.sum().backward()
updater(X.shape[0])
metric.add(float(l.sum()), accuracy(y_hat, y), y.numel())
# 返回训练损失和训练精度
return metric[0] / metric[2], metric[1] / metric[2]
然后我们再定义一个Animator函数来可视化训练的过程:
class Animator: #@save
"""在动画中绘制数据"""
def __init__(self, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), nrows=1, ncols=1,
figsize=(3.5, 2.5)):
# 增量地绘制多条线
if legend is None:
legend = []
d2l.use_svg_display()
self.fig, self.axes = d2l.plt.subplots(nrows, ncols, figsize=figsize)
if nrows * ncols == 1:
self.axes = [self.axes, ]
# 使用lambda函数捕获参数
self.config_axes = lambda: d2l.set_axes(
self.axes[0], xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
self.X, self.Y, self.fmts = None, None, fmts
def add(self, x, y):
# 向图表中添加多个数据点
if not hasattr(y, "__len__"):
y = [y]
n = len(y)
if not hasattr(x, "__len__"):
x = [x] * n
if not self.X:
self.X = [[] for _ in range(n)]
if not self.Y:
self.Y = [[] for _ in range(n)]
for i, (a, b) in enumerate(zip(x, y)):
if a is not None and b is not None:
self.X[i].append(a)
self.Y[i].append(b)
self.axes[0].cla()
for x, y, fmt in zip(self.X, self.Y, self.fmts):
self.axes[0].plot(x, y, fmt)
self.config_axes()
display.display(self.fig)
display.clear_output(wait=True)
接下来我们实现一个训练函数, 它会在train_iter访问到的训练数据集上训练一个模型net。 该训练函数将会运行多个迭代周期(由num_epochs指定)。 在每个迭代周期结束时,利用test_iter访问到的测试数据集对模型进行评估。 我们将利用Animator类来可视化训练进度。
def train_ch3(net, train_iter, test_iter, loss, num_epochs, updater): #@save
"""训练模型"""
animator = Animator(xlabel='epoch', xlim=[1, num_epochs], ylim=[0.3, 0.9],
legend=['train loss', 'train acc', 'test acc'])
for epoch in range(num_epochs):
train_metrics = train_epoch_ch3(net, train_iter, loss, updater)
test_acc = evaluate_accuracy(net, test_iter)
animator.add(epoch + 1, train_metrics + (test_acc,))
train_loss, train_acc = train_metrics
assert train_loss < 0.5, train_loss
assert train_acc <= 1 and train_acc > 0.7, train_acc
assert test_acc <= 1 and test_acc > 0.7, test_acc
我们使用之前深度学习:线性回归中所定义的小批量随机梯度下降来优化参数。其中,设置学习率lr为0.1。
lr = 0.1 # 学习率
def updater(batch_size):
return d2l.sgd([W, b], lr, batch_size)
现在,我们训练模型10个迭代周期。 请注意,迭代周期(num_epochs)和学习率(lr)都是可调节的超参数。 通过更改它们的值,我们可以提高模型的分类精度。
num_epochs = 10
train_ch3(net, train_iter, test_iter, cross_entropy, num_epochs, updater)
### 模型的训练完成
现在,模型已经训练完毕。我们的目标是使用它对图像进行分类预测。
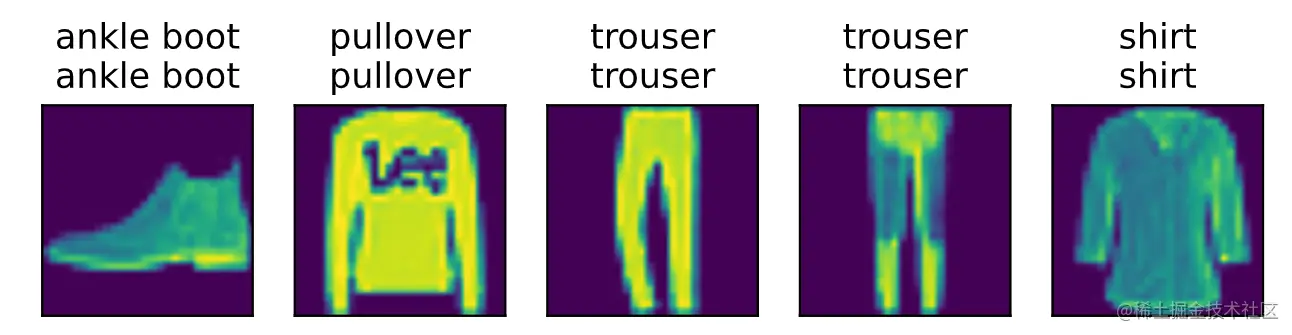
给定一组图像,我们将比较它们的实际标签(文本输出的第一行)和模型预测(文本输出的第二行)。
```python
def predict_ch3(net, test_iter, n=6): #@save
"""预测标签"""
for X, y in test_iter:
break
trues = d2l.get_fashion_mnist_labels(y)
preds = d2l.get_fashion_mnist_labels(net(X).argmax(axis=1))
titles = [true +'\n' + pred for true, pred in zip(trues, preds)]
d2l.show_images(
X[0:n].reshape((n, 28, 28)), 1, n, titles=titles[0:n])
```
### 预测标签
在给定一组图像后,我们将执行以下操作:
1. **实际标签**(文本输出的第一行):我们获取真实标签,并将其转换为更易读的表示。
2. **模型预测**(文本输出的第二行):使用模型对输入数据进行最大概率的预测,即通过计算每个类别的概率来确定其类别。
3. **比较结果**:将实际标签与模型预测的标签进行比较,生成一个列表,其中包含真实标签和对应的预测标签。
通过调用 `predict_ch3` 函数并传入适当的参数(例如图像数量),我们可以查看模型的预测情况。
### 8. 总结
在本文中,我们深入探讨了 softmax 回归模型的基本原理和实现方法。softmax回归主要用于离散分类问题,而线性回归则适用于预测连续数值。
### 9. 参考资料
1. **《动手学深度学习》 Release2.0.0-beta0**
2. **softmax 回归原理及损失函数**
3. **神经网络与深度学习_邱锡鹏**
4. **深度学习:线性回归**